
Все, что вам нужно знать о поколоночных индексах, в одной статье
Пересказ статьи Gail. All you need to know about Columnstore Indexes in one article
Я осознал, что, несмотря на обилие публикаций об индексах за многие годы, я никогда не писал в блоге о поколоночных (Columnstore) индексах. Время исправить это. Здесь все, что вам нужно знать, чтобы начать использовать поколоночные индексы. (Обратите внимание, это никоим образом не вообще все, что нужно знать об индексах columnstore. Для этого см. серию блогов Nico, в настоящее время насчитывающую 131 публикацию).
Прежде чем углубиться в поколоночные индексы, позвольте мне для сравнения обсудить построчные (rowstore) индексы.
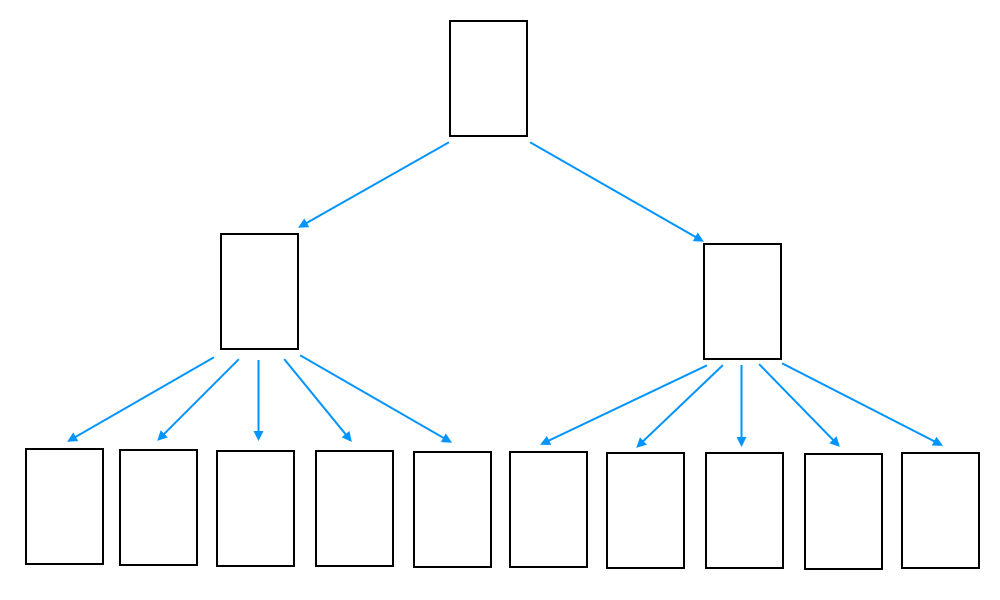
В построчном индексе (который раньше мы называли просто индекс) страницы находятся в B-Tree, листовые уровни которого содержат все строки, а верхние уровни содержат по одной строке на страницу, находящуюся ниже.
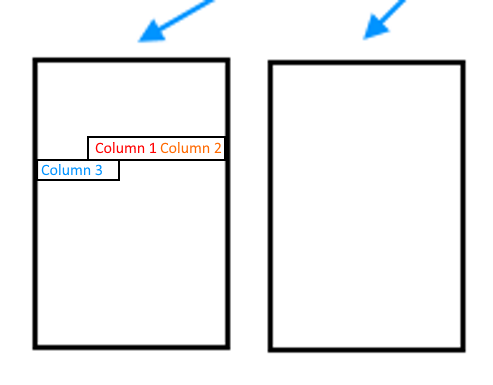
Столбцы, которые составляют строку (или, по крайней мере, те, которые являются частью индекса), находятся все вместе на странице. Следовательно, для получения одного столбца из индекса приходится читать всю страницу и все остальные столбцы, которые являются частью этого индекса.
Поколоночные индексы...не такие.
Во-первых, и я должен сказать, что наиболее важной вещью для понимания поколоночных индексов, является то, что они не имеют ключей. Это не поисковые индексы. Любой доступ к поколоночному индексу должен быть сканированием.
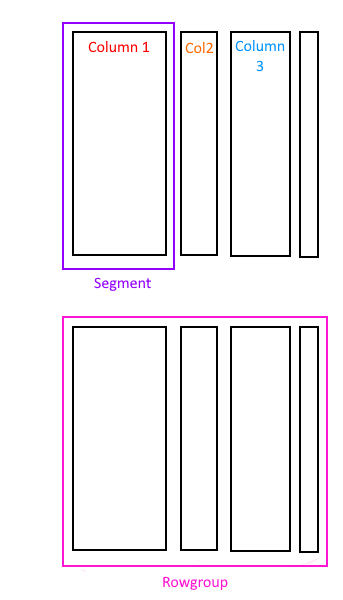
Вместо хранения строк вместе на странице, поколоночный индекс хранит вместе значения столбца. Все строки в таблице разбиваются на куски (chunks) максимум в миллион строк, называемых группой строк, а столбцы затем сохраняются отдельно в том, что называется сегментами. Сегмент всегда будет содержать значения только одного столбца.
Затем сегменты сжимаются, и, поскольку обычно в столбце значения повторяются, они сжимаются достаточно хорошо.
В результате такой архитектуры, если запросу требуется получить все значения столбца 2 и столбца 3, это очень эффективный доступ. Могут быть прочитаны все сегменты, которые содержат столбец 2 и столбец 3, в то время как сегменты, содержащие другие столбцы могут быть полностью проигнорированы. С другой стороны, если запросу нужны все столбцы для небольшого числа строк, это будет совершенно неэффективный доступ. Поскольку нет способа поиска в поколоночном индексе, все сегменты должны быть прочитаны* для локализации значений столбца, которые составляют строку, и строка должна быть реконструирована.
(*)Существует процесс, называемый исключением групп строк, который может удалять группы строк из рассмотрения при локализации строк. Я не будут вдаваться в подробности этого процесса в данной статье.
Индекс в этой форме является нередактируемым, во всяком случае, это непросто. Все столбцы сжаты, поэтому изменение отдельного значения потребует декомпрессии всего сегмента, прежде чем значение будет обновлено. Первая версия поколоночных индексов была на самом деле только для чтения, что делало эти индексы малополезными во многих случаях. Поэтому, начиная с SQL2014, поколоночные индексы являются обновляемыми. Вроде.
Ну, сжатые сегменты не являются обновляемыми, в них нельзя ничего добавить или удалить. Непосредственно то есть. Вместо этого новые строки добавляются к так называемому «дельта-хранилищу», которое представляет собой индекс B-Tree, связанный с поколоночным хранилищем. Вновь вставляемые строки добавляются в дельта-хранилище, а не в сжатые сегменты непосредственно. Как только дельта-хранилище достигает определенного размера, оно закрывается, сжимается и содержимое добавляется в поколоночный индекс в качестве новой группы строк. Удаление обрабатывается подобный образом. Когда строка удаляется, в битовой карте удалений устанавливается флажок, указывающий, что строка больше не существует. При чтении индекса любые строки, помеченные как удаленные в битовой карте, убираются из результирующего набора. Обновления разбиваются на удаления и вставки, следовательно, флаг удаления устанавливается для старой версии строки, а затем новая версия строки вставляется в дельта-хранилище.
Перестройка индекса будет заново создавать все группы строк и удалять логически удаленные строки, а также принудительно сжимать все открытые группы строк. Операции реорганизации индекса будут принудительно сжимать открытые группы и удалять логически удаленные строки, если более 10% строк в файловой группе помечены как удаленные.
Пока все хорошо, к чему беспокоиться? Простой ответ - это скорость. Поколоночные индексы являются быстрыми для операций с большим числом строк по следующим причинам:
Первое мы уже рассмотрели. Когда запросу требуется бОльшая часть строк в таблице, но только небольшая часть столбцов, хранилище на базе столбцов оказывается более эффективным.
Сжатие - это вторая причина. Поколоночные индексы сжимаются, и поскольку здесь есть больше возможностей сжатия хранящихся вместе значений столбца, чем для строк, они обычно сжимаются очень хорошо. Хорошее сжатие означает, что требуется перемещать меньше данных, что обычно приводит к лучшей производительности.
Третья причина - пакетный режим. Пакетный режим - это функция процессора запросов, когда множество строк могут обрабатываться одновременно, а не построчно. Это может быть значительно быстрей, чем при построчной режиме. Когда появилось поколоночное хранилище, пакетный режим мог применяться только в запросах к поколоночному индексу, однако, начиная с SQL 2017, пакетный режим стал доступен также и для построчных индексов.
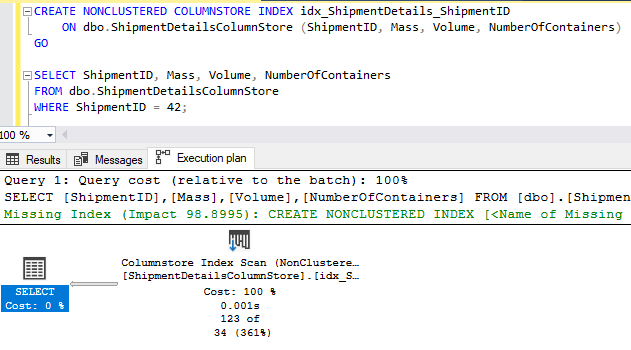
Насколько быстрей? Ну...
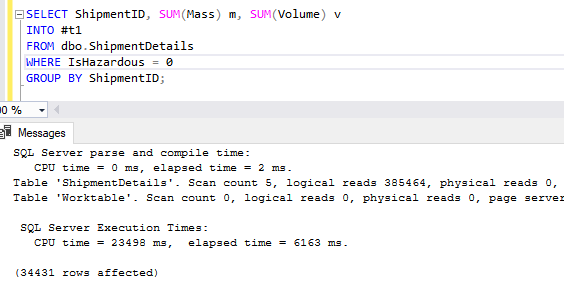
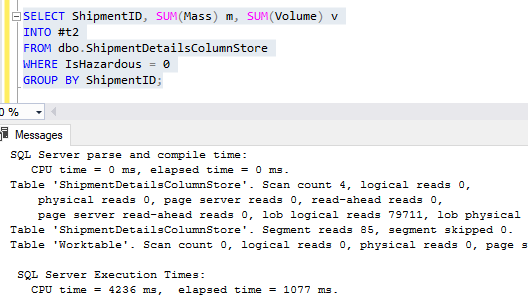
Единственное отличие двух запросов выше заключается в том, что один выполняется к таблице с построчным кластеризованным индексом, а другой - к таблице с поколоночным кластеризованным индексом. О, и 19 секунд времени ЦП. Обе таблицы имели в точности одинаковые данные, 88 миллионов строк.
В построчном индексе (который раньше мы называли просто индекс) страницы находятся в B-Tree, листовые уровни которого содержат все строки, а верхние уровни содержат по одной строке на страницу, находящуюся ниже.
Столбцы, которые составляют строку (или, по крайней мере, те, которые являются частью индекса), находятся все вместе на странице. Следовательно, для получения одного столбца из индекса приходится читать всю страницу и все остальные столбцы, которые являются частью этого индекса.
Поколоночные индексы...не такие.
Во-первых, и я должен сказать, что наиболее важной вещью для понимания поколоночных индексов, является то, что они не имеют ключей. Это не поисковые индексы. Любой доступ к поколоночному индексу должен быть сканированием.
Вместо хранения строк вместе на странице, поколоночный индекс хранит вместе значения столбца. Все строки в таблице разбиваются на куски (chunks) максимум в миллион строк, называемых группой строк, а столбцы затем сохраняются отдельно в том, что называется сегментами. Сегмент всегда будет содержать значения только одного столбца.
Затем сегменты сжимаются, и, поскольку обычно в столбце значения повторяются, они сжимаются достаточно хорошо.
В результате такой архитектуры, если запросу требуется получить все значения столбца 2 и столбца 3, это очень эффективный доступ. Могут быть прочитаны все сегменты, которые содержат столбец 2 и столбец 3, в то время как сегменты, содержащие другие столбцы могут быть полностью проигнорированы. С другой стороны, если запросу нужны все столбцы для небольшого числа строк, это будет совершенно неэффективный доступ. Поскольку нет способа поиска в поколоночном индексе, все сегменты должны быть прочитаны* для локализации значений столбца, которые составляют строку, и строка должна быть реконструирована.
(*)Существует процесс, называемый исключением групп строк, который может удалять группы строк из рассмотрения при локализации строк. Я не будут вдаваться в подробности этого процесса в данной статье.
Индекс в этой форме является нередактируемым, во всяком случае, это непросто. Все столбцы сжаты, поэтому изменение отдельного значения потребует декомпрессии всего сегмента, прежде чем значение будет обновлено. Первая версия поколоночных индексов была на самом деле только для чтения, что делало эти индексы малополезными во многих случаях. Поэтому, начиная с SQL2014, поколоночные индексы являются обновляемыми. Вроде.
Ну, сжатые сегменты не являются обновляемыми, в них нельзя ничего добавить или удалить. Непосредственно то есть. Вместо этого новые строки добавляются к так называемому «дельта-хранилищу», которое представляет собой индекс B-Tree, связанный с поколоночным хранилищем. Вновь вставляемые строки добавляются в дельта-хранилище, а не в сжатые сегменты непосредственно. Как только дельта-хранилище достигает определенного размера, оно закрывается, сжимается и содержимое добавляется в поколоночный индекс в качестве новой группы строк. Удаление обрабатывается подобный образом. Когда строка удаляется, в битовой карте удалений устанавливается флажок, указывающий, что строка больше не существует. При чтении индекса любые строки, помеченные как удаленные в битовой карте, убираются из результирующего набора. Обновления разбиваются на удаления и вставки, следовательно, флаг удаления устанавливается для старой версии строки, а затем новая версия строки вставляется в дельта-хранилище.
Перестройка индекса будет заново создавать все группы строк и удалять логически удаленные строки, а также принудительно сжимать все открытые группы строк. Операции реорганизации индекса будут принудительно сжимать открытые группы и удалять логически удаленные строки, если более 10% строк в файловой группе помечены как удаленные.
Пока все хорошо, к чему беспокоиться? Простой ответ - это скорость. Поколоночные индексы являются быстрыми для операций с большим числом строк по следующим причинам:
- Хранилище на основе столбца
- Сжатие
- Пакетный режим обработки запроса
Первое мы уже рассмотрели. Когда запросу требуется бОльшая часть строк в таблице, но только небольшая часть столбцов, хранилище на базе столбцов оказывается более эффективным.
Сжатие - это вторая причина. Поколоночные индексы сжимаются, и поскольку здесь есть больше возможностей сжатия хранящихся вместе значений столбца, чем для строк, они обычно сжимаются очень хорошо. Хорошее сжатие означает, что требуется перемещать меньше данных, что обычно приводит к лучшей производительности.
Третья причина - пакетный режим. Пакетный режим - это функция процессора запросов, когда множество строк могут обрабатываться одновременно, а не построчно. Это может быть значительно быстрей, чем при построчной режиме. Когда появилось поколоночное хранилище, пакетный режим мог применяться только в запросах к поколоночному индексу, однако, начиная с SQL 2017, пакетный режим стал доступен также и для построчных индексов.
Насколько быстрей? Ну...
Единственное отличие двух запросов выше заключается в том, что один выполняется к таблице с построчным кластеризованным индексом, а другой - к таблице с поколоночным кластеризованным индексом. О, и 19 секунд времени ЦП. Обе таблицы имели в точности одинаковые данные, 88 миллионов строк.
Обратные ссылки
Автор не разрешил комментировать эту запись
Комментарии
Показывать комментарии Как список | Древовидной структурой