Пересказ статьи Grant Fritchey. Can AI Read Execution Plans?
Да, да, вторая статья об ИИ подряд. Я обещаю, что это не станет привычкой. Но я видел, что кто-то еще упомянул, что вы можете подать XML, и ИИ прочитает план выполнения. Я должен был протестировать это, а затем поделиться результатами с вами.
Продолжить чтение "Может ли ИИ читать планы выполнения?"
Пересказ статьи Lorenzo Uriel. The SQL Week: Bitmasking & Bitwise
Поразрядное маскирование (Bitmasking) и побитовые (Bitwise) операции являются понятиями, используемыми главным образом в программировании для манипуляции и представления данных и объектов на уровне битов, позволяя эффективно их обрабатывать.
Поразрядным маскированием называется процесс использования битовой маски для манипуляции или проверки значения конкретных битов в двоичном числе.
Это делается с помощью побитовых операторов, таких как AND (&), OR (|), XOR (^), NOT (~) и других. Битовые маски используются для определения того, какие биты числа будут модифицироваться, тестироваться или включаться.
Продолжить чтение "Неделя SQL: поразрядное маскирование и побитовые операции"
Пересказ статьи Grant Fritchey. Exploring Window Functions Execution Plans
Есть совсем немного разных способов, с помощью которых вы, вероятно, могли увидеть, как оконные функции проявляют себя в плане выполнения. Давайте рассмотрим один пример.
Оконные функции
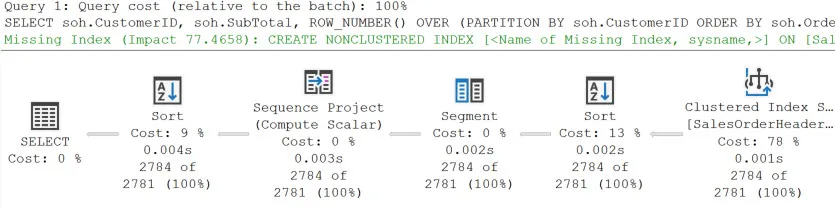
Для нашего примера я возьму довольно простой запрос:
SELECT soh.CustomerID,
soh.SubTotal,
ROW_NUMBER() OVER (PARTITION BY soh.CustomerID ORDER BY soh.OrderDate ASC) AS RowNum,
Soh.OrderDate
FROM Sales.SalesOrderHeader AS soh
WHERE soh.OrderDate
BETWEEN '1/1/2013' AND '7/1/2013'
ORDER BY RowNum DESC, soh.OrderDate;
Ничего необычного. Какой план будет сгенерирован? Вот план с метриками времени выполнения (т.е. действительный план):
 Продолжить чтение "Изучение планов выполнения оконных функций"
Продолжить чтение "Изучение планов выполнения оконных функций"
Пересказ статьи Nisarg Upadhyay. How to Rename a Column in SQL Server
Недавно я работал над проектом по анализу схемы стороннего поставщика. В нашей организации имелся инструмент управления внутренними тикетами поддержки. Этот инструмент использовал базу данных SQL, и после оценки стоимости инструмента мы решили не возобновлять контракт. Планировалось создать собственный инструмент для управления внутренними тикетами поддержки.
Я должен был сделать обзор схемы базы данных внутренней поддержки. Структура была очень сложной, а имена таблиц таковы, что нам затруднительно было понять, какие данные в каких таблицах хранятся. В конце концов я смог определить связи между таблицами и какие данные там находились. Я также позаботился о том, чтобы дать подходящие имена столбцам, чтобы мы могли легко находить требуемые данные. Я использовал процедуру sp_rename для переименования таблиц.
Эта статья посвящена основам переименования столбцов с помощью хранимой процедуры sp_rename. Также я объясняю, как переименовать столбец, используя SQL Server Management Studio. Сначала давайте разберемся с основами переименования столбца.
Продолжить чтение "Как переименовать столбец в SQL Server"
Пересказ статьи Joydip Kanjilal. SQL Server TRY CATCH, RAISERROR and THROW for Error Handling
Ошибки в приложениях SQL Server могут возникать по разным причинам, таким как ошибочные данные, несогласованность данных, сбой системы или других ошибок. Здесь мы разберем, как обрабатывать ошибки в SQL Server при помощи TRY…CATCH, RAISERROR и THROW.
Логика T-SQL позволяет обрабатывать ошибки в SQL Server разными способами, такими как блоки TRY…CATCH, операторы RAISERROR и THROW. Каждый вариант имеет свои достоинства и недостатки. Давайте рассмотрим примеры для каждого варианта.
Продолжить чтение "TRY CATCH, RAISERROR и THROW для обработки ошибок в SQL Server"
Пересказ статьи Edward Pollack. Effective Strategies for Storing and Parsing XML in SQL Server
XML представляет собой общепринятый формат хранения для данных, метаданных, параметров или других полуструктурированных данных. По этой причине он часто попадает в базы данных SQL Server и возникает потребность в его обслуживании наряду с другими типами данных.
Несмотря на то, что реляционные базы данных не являются оптимальным местом хранения и обработки данных XML, такая необходимость возникает из-за требований приложения, удобства или необходимости держать эту информацию в непосредственной близости с другими данными приложения.
В этой статье рассматриваются различные распространенные проблемы, связанные с XML, и функциональность, которой обладает SQL Server, чтобы максимально упростить решение этих проблем.
Продолжить чтение "Эффективные стратегии хранения и парсинга XML в SQL Server"
Пересказ статьи Koen Verbeeck. SQL Server JSON Functions JSON_OBJECTAGG and JSON_ARRAYAGG
Мне необходимо построить JSON из данных, находящихся в базе данных, но оказалось, что существующая конструкция FOR JSON PATH ограничена, когда данные не находятся в одной единственной строке, а разбросаны по множеству строк. Есть ли другой метод обработки данных JSON в SQL Server? Узнайте, как использовать новые функции JSON в SQL Server - JSON_OBJECTAGG и JSON_ARRAYAGG.
Были введены две новые функции T-SQL для создания документов JSON из имеющихся данных: JSON_OBJECTAGG и JSON_ARRAYAGG. Обе являются агрегатными функциями, которые помогают создать представления JSON из данных, хранящихся в множестве строк.
Здесь мы познакомимся с обоими функциями. На момент написания статьи эти функции доступны только в Azure SQL DB, Azure SQL Managed Instance и Fabric SQL Database. Эти функции должны быть включены в следующие версии SQL Server.
Продолжить чтение "Функции JSON_OBJECTAGG и JSON_ARRAYAGG в SQL Server"
Пересказ статьи Jared Westover. Replace SQL Cursors with Set Based Operations – OUTPUT and MERGE
Курсоры имеют плохую репутацию в SQL Server, и вполне залуженную. Они находят свое применение в таких областях, как выполнение задач по обслуживанию баз данных. Я избегаю их, когда дело касается стандартного кода T-SQL. Проблемы производительности становятся заметными при работе с таблицами сколь-нибудь заметного размера. Если вы имеете за спиной более процедурный язык, бывает трудно думать не в терминах курсора. Но не беспокойтесь, есть надежда.
В этой статье я хочу сделать обзор типичного паттерна, который мы все видели. Он включает использование курсора или цикл WHILE для вставки или обновления данных. Начнем с того, чтобы разобраться, почему разработчик может по умолчанию начинать с курсора. Далее я построю типичный курсор для решения этой задачи. Затем мы разберемся, как можно быстрей достичь того же вывода с помощью операции на основе множеств.
Продолжить чтение "Замена курсоров SQL операциями на основе множеств - OUTPUT и MERGE"
Пересказ статьи Cláudio Silva. What happens when we drop a column on a SQL Server table? Where's my space
Короткий ответ: столбец отмечается как "удаленный" и перестанет быть видимым/используемым. Но, что наиболее важно - размер записи/таблицы останется неизменным.
Операция с метаданными
Удаление столбца является логической операцией с метаданными, а не физической. Это означает, что данные не удаляются/перезаписываются при этом действии. Если говорить об удалении данных (записей), то как упоминает
здесь Пол Рэндал:
«стоимость этого будет отложена для вставляющих, а не для удаляющих».
Продолжить чтение "Что происходит при удалении столбца в таблице SQL Server? Где мое пространство?"
Пересказ статьи Hugo Kornelis. Plansplaining part 30 – Static cursors
В части 30 серии
plansplaining мы продолжим обсуждение обработки курсоров. Я рекомендую вам сначала прочитать
предыдущую статью, где я излагаю основы.
Тестовый запрос
В этой серии я буду придерживаться использования одного и того же тестового запроса, который выводит данные по продажам и товарам, которые были проданы в количестве более 10 единиц в пределах заданного диапазона заказов.
Продолжить чтение "Статические курсоры"
Пересказ статьи Rick Dobson. SQL Bulk Insert Command Examples
Оператор BULK INSERT в T-SQL специально разработан для переноса содержимого больших файлов в таблицы SQL Server. Однако операторы bulk insert могут использоваться как для больших файлов, так и для малых и/или множества файлов среднего размера. Если вы предпочитаете программировать на T-SQL или считаете, что SSIS - это слишком тяжело для некоторых из ваших проектов по импорту файлов, операторы bulk insert могут предоставить нужный уровень поддержки и дать выигрыш в производительности.
Здесь представлены еще три практических примера использования bulk insert. В конце статьи есть ссылка на скачивание тестовых данных для каждого примера случая использования и дополнительные наборы данных для практики с ними.
Продолжить чтение "Примеры команды SQL Bulk Insert"
Пересказ статьи Eitan Blumin. SQL Server Index Mastery: Choosing the Right Column Order
Введение
Оптимизация производительности SQL Server - непростая тема, и проектирование индексов играет в ней жизненно важную роль, способствуя эффективности выполнения запросов к базе данных.
Одним из ключевых аспектов, которые часто влияют на производительность, является порядок столбцов в индексе.
В этом руководстве я буду использовать мой реальный опыт работы консультантом для исследования мыслительного процесса, стоящего за выбором лучшей последовательности столбцов в индексе, логики принятия решений и предложения некоторых практических решений для достижения оптимальной производительности базы данных.
Продолжить чтение "Мастерство работы с индексами в SQL Server: выбор правильного порядка столбцов"
Пересказ статьи Chad Callihan. What is the OPTION (FAST N) Query Hint?
Как вы познакомились с хинтом запроса OPTION (FAST N)? Я никогда его не использовал раньше, поэтому решил немного поэкспериментировать с ним. Давайте посмотрим, что он делает, и как его применять в запросе.
Что такое OPTION (FAST N)
При использовании хинта запроса OPTION (FAST N) SQL Server пытается сфокусироваться на получении N строк. Пусть, например, я выполняю запрос, который должен вернуть сотни строк. Я могу захотеть посмотреть первые 50 или около того как можно быстрее с тем, чтобы начать анализировать их, пока запрос завершает получение остальных строк.
Продолжить чтение "Что делает хинт запроса OPTION (FAST N)?"
Пересказ статьи Simon Liew. SQL Server Filtered Index Essentials Guide
Фильтрованные индексы могут значительно повысить производительность запроса, но простые ошибки могут помешать их использованию. Мы поможем вам понять, как использовать фильтрованные индексы SQL Server и выявить запросы, которые могут получить от этого преимущество, которого они не имели.
Фильтрованные индексы - это обычные некластеризованные индексы, которые содержат только подмножество данных (фильтрованные данные). Фильтрованные индексы особенно полезны для узкого покрытия запроса, который требует быстрого извлечения и высокой доступности.
Ключом для правильного использования оптимизатором SQL Server фильтрованных индексов является:
- Убедиться, то предикат (предикаты) запроса эквивалентны выражению фильтрованного индекса. Иногда предикат не должен точно совпадать с выражением, и оптимизатор SQL Server может определить это. Однако чем проще, тем лучше.
- Предикат ((предикаты) запроса на столбце (столбцах) фильтрованного индекса не параметризуются или не используют присвоение переменной.
Продолжить чтение "Фильтрованные индекс в SQL Server: основы"
Пересказ статьи Erik Darling. The How To Write SQL Server Queries Correctly Cheat Sheet Conditional Join and Where Clauses
Так или иначе
Оператор OR вполне легитимно может использоваться в операторах SQL. Если вы используете предложение IN, велика вероятность, что оптимизатор преобразует его в последовательность операторов OR.
Например, IN(1, 2, 3) может в результате стать = 1 OR = 2 OR = 3 без вашего участия. Оптимизаторы так забавляются. Забавные маленькие кролики.
Проблема обычно возникает не тогда, когда вы пишете в запросе IN или OR для одного столбца со списком литеральных значений, а когда вы:
- Используете OR по множеству столбцов в предложении WHERE.
- Используете OR в предложении JOIN любого сорта.
- Используете OR для обработки параметров или переменных NULL.
Добавьте немного сложности, объединив две таблицы и попросив что-то вроде:
Продолжить чтение "Шпаргалка по правильному написанию запросов к SQL Server: условное соединение и предложение WHERE"
