Пересказ статьи Ismail. Using AI to Decode PostgreSQL Query Performance: A Practical Guide

Оптимизация запросов является одной из наиболее сложных сторон работы с базами данных. PostgreSQL дает вам мощные инструменты типа pg_stat_statements и EXPLAIN ANALYZE для понимания и настройки производительности запросов. И хотя эти инструменты содержат ценную информацию, ее бывает сложно интерпретировать - особенно под давлением.
Включите инструменты ИИ. Благодаря возможностям естественного языка и растущего понимания контекста, ИИ может помочь расшифровать то, что стоит за статистикой, выявляя медленные запросы, неэффективные операции и даже предлагая потенциальные улучшения.
В этой статье мы выясним, как можно сочетать исследовательские инструменты PostgreSQL с ИИ, чтобы выполнить настройку более быстро, чисто и продуктивно.
Продолжить чтение "Использование ИИ для декодирования производительности запросов в PostgreSQL: практическое руководство"
Пересказ статьи Anjuman Bhattacharyya. Statement Timeout in PostgreSQL
Необходимо предохранять вашу базу данных от долгоиграющих запросов, т.к. они могут подвесить ее. Для защиты вашей базы данных PostgreSQL имеется один конфигурационный параметр, устанавливающий максимально дозволенную длительность любого исполняющегося запроса. Это параметр statement_timeout.
Конфигурационный параметр: statement_timeout
Описание: Устанавливает максимально допустимую продолжительность любого оператора.
Значение по умолчанию: 0 (0 означает, что параметр выключен; обычно измеряется в мс; в основном указывается в мс или сек).
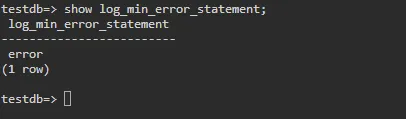
PostgreSQL также записывает в журнал запрос, время ожидания которого истекло, если другой параметр
log_min_error_statement установлен в ERROR. Вы можете проверить это, выполнив следующую команду в вашей базе данных.
 Продолжить чтение "Тайм-аут оператора в PostgreSQL"
Продолжить чтение "Тайм-аут оператора в PostgreSQL"
Пересказ статьи Nathan Rosidi. Integrating Python with SQL for Robust Data Solutions
"Данные - это новая нефть", - говорит Clive Humby. Python и SQL важны для переработки этой нефти, но почему не использовать их совместно?
Для тех, кто ищет решения для манипуляции базами SQL с помощью Python и SQL, мы исследуем различные подходы и используем один из них для создания вопроса для интервью.
Но прежде давайте рассмотрим преимущества и варианты подключения к базам данных с помощью Python.
Продолжить чтение "Интеграция Python с SQL для надежных решений по работе с данными"
Пересказ статьи Semab Tariq. Performance impact of using ORDER BY with LIMIT in PostgreSQL
При запросах к большим наборам данных в PostgreSQL сочетание предложений ORDER BY и LIMIT может существенно влиять на производительность. ORDER BY сортирует данные, а LIMIT ограничивает число возвращаемых строк, но вместе они создают узкое место в производительности. Понимание взаимодействия этих операций и оптимизация их использования представляется весьма важным для поддержания эффективной производительности базы данных и гарантии быстрого выполнения запросов.
В этой статье мы рассмотрим, как они могут повлиять на производительность запроса.
Ниже приведена структура простой таблицы с именем person, которая будет использоваться в наших тестах.
Продолжить чтение "Влияние на производительность использования ORDER BY с LIMIT в PostgreSQL"
Пересказ статьи Tarik Favero. PostgreSQL Execution plan algorithms
В этой статье описываются наиболее общие алгоритмы, которые PostgreSQL может использовать в плане выполнения данного запроса. Примите к сведению, что это не полный список; позднее могут быть добавлены другие алгоритмы.
Алгоритмы пути доступа
Все планы выполнения описывают способ доступа к данным для обеспечения вывода результатов запроса. Поэтому мы обнаружим список операторов, которые выполнялись или будут выполняться для получения результатов.
Мы увидим такие алгоритмы доступа к данным, как Seq Scan, Index Scan, Index-only scan, Bitmap index scan, Bitmap heap scan и их параллельные реализации. В зависимости от условий соединения в JOIN мы увидим алгоритмы комбинации таблиц, такие как Nested loop, Hash-join и Merge. Кроме того, будет представлена информация относительно агрегации, сортировки и буферизации.
Каждый алгоритм имеет свои собственные особенности, которые в зависимости от множества факторов могут оказаться более или менее производительными. Давайте более подробно рассмотрим каждый алгоритм доступа.
Продолжить чтение "Алгоритмы плана выполнения в PostgreSQL"
Пересказ статьи Maly Mohsem Ahmed. Enhancing Logging Functionality with PostgreSQL 15’s new JSON Logging Feature
В PostgreSQL появилась новая замечательная функция: журнализация JSON. Хотя журналы JSON занимают больше места, чем журналы в традиционных форматах, они предлагают значительные улучшения, такие как облегчение парсинга и обработки. Эта возможность появилась, начиная с PostgreSQL 15.
Конфигурирование журнализации JSON
Чтобы включить журнализацию JSON, вам необходимо настроить файл postgresql.conf следующим образом:
log_destination = 'jsonlog' # Доступные значения: сочетание stderr, csvlog, jsonlog, syslog и eventlog (независимо от платформы).
logging_collector = on # Требуется для захвата stderr, jsonlog и csvlog в файлы журнала. Это должно быть включено для csvlog и jsonlog.
С этими настройками вывод из журнала может выглядеть следующим образом:
Продолжить чтение "Улучшение функциональности журнализации с помощью новой функции JSON в PostgreSQL 15"
Пересказ статьи DbVisualizer. Using hstore for Storing Unstructured Data in PostgreSQL
В PostgreSQL тип данных hstore является мощным средством для хранения пар ключ-значение в одном столбце, идеальным для управления полуструктурированными и неструктурированными данными. В этой статье дается обзор hstore, содержащий его использование, включение и практические примеры его приложения.
Что такое hstore в PostgreSQL?
hstore позволяет сохранять пары ключ-значение в строковом формате в одном столбце. Эта гибкость идеально удовлетворяет пожеланиям пользователей, хорошо подходит для хранения конфигурационных параметров или метаданных. Вот простой пример:
ALTER TABLE users ADD COLUMN metadata hstore;
Продолжить чтение "Использование hstore для хранения неструктурированных данных в PostgreSQL"
Пересказ статьи Hagen Hübel. Understanding the Performance Difference in Adding Columns in PostgreSQL
Оптимизация производительности базы данных крайне важна, особенно, когда речь идет о больших таблицах. Многие администраторы баз данных и разработчики знакомы с типичным сценарием добавления новых столбцов в существующие таблицы . Недавно я столкнулся с интересной ситуацией в PostgreSQL, которая позволила увидеть то, как база данных обрабатывает добавление и обновление столбцов. Вот что я обнаружил, и почему это важно.
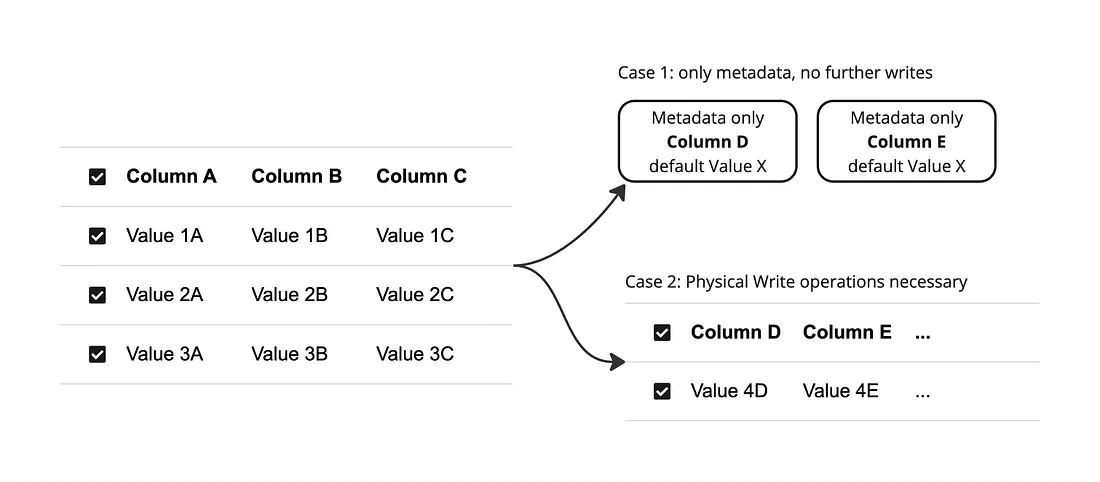
Вопрос
Представьте, что у вас есть большая таблица, содержащая десятки тысяч записей. Вы хотите добавить новый допускающий NULL-значения столбец без значения по умолчанию, а затем выполнить оператор UPDATE, чтобы установить для этого нового столбца заданное значение. Этот процесс занимает значительное время. Однако, если вы вместо этого добавляете новый столбец со значением по умолчанию, это не занимает так много времени. Почему имеет место такая разница в производительности?
Продолжить чтение "Понимание разницы в производительности при добавлении столбцов в PostgreSQL"
Пересказ статьи Peyman. date_trunc function in PostgreSQL
Недавно мне потребовалось написать запрос SQL для получения множества данных из большой таблицы за конкретный интервал времени. Я не знаю, есть ли более простой способ в SQL, чтобы сделать это, я же обнаружил в PostgreSQL функцию date_trunc, которая является отличным решением моей проблемы.
Проблема на примере
Рассмотрим следующую таблицу.
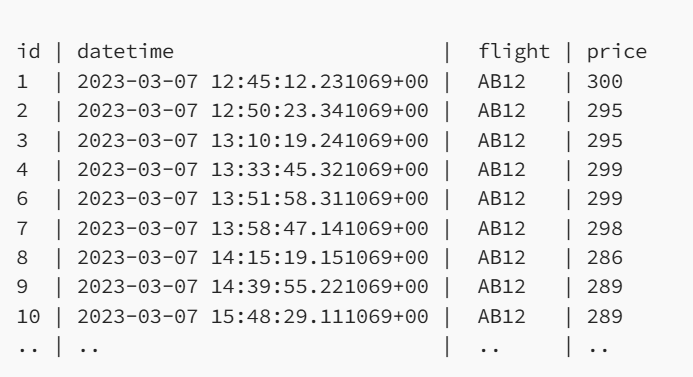
И мы хотим получить по одной строке в час (или последнюю цену для каждого часа) для полета AB12. Вывод должен выглядеть примерно так.
 Продолжить чтение "Функция date_trunc в PostgreSQL"
Продолжить чтение "Функция date_trunc в PostgreSQL"
Пересказ статьи Yash Marathe. Generalized Inverted Index in PostgreSQL
Исследование достоинств и недостатков GIN-индексов в PostgreSQL
Содержание
- Мотивация
- Введение
- GIN-индексирование изнутри
- Практический пример
- Уроки индекса GIN Trigram GitLab
- Заключение
- Ссылки
Продолжить чтение "Обобщенный инвертированный индекс в PostgreSQL"
Пересказ статьи Yasin Sari. LATERAL as an Advanced SQL Feature
Я всегда представляю себе аналитика данных человеком, который имеет правильный инструмент для решения реальных проблем, во многом подобный швейцарскому армейскому ножу. Lateral - это одна из функций стандарта ANSI SQL, которая вам может пригодиться в некоторых случаях, поскольку она помогает легко решать проблемы. Я хочу продемонстрировать ее на нескольких примерах, чтобы показать, как она может улучшить анализ данных, обеспечив большую гибкость, скорость, сократить время и так далее.
Тематика
- SQL
- PIVOT
- PostgreSQL
- LATERAL JOIN
- Коррелирующие подзапросы
Продолжить чтение "LATERAL как расширенная функция SQL"
Пересказ статьи MyFaduGame. Mastering FastAPI CRUD Operations with Async SqlAlchemy and PostgreSQL
В этом подробном руководстве мы познакомимся с построением надежных операций CRUD (Create, Read, Update, Delete) с помощью FastAPI, используя мощь Async SqlAlchemy и интеграцию с PostgreSQL для высокопроизводительного асинхронного взаимодействия с базой данных.
Мы разделим наш проект Fruit Full на несколько этапов:
- Введение в FastAPI и Async SqlAlchemy: Мы начнем с введения в FastAPI, современный, высокопроизводительный фреймворк Python для построения API, и Async SqlAlchemy, асинхронную версию SqlAlchemy, которая допускает неблокирующие операции с базой данных.
- Установка проекта: Мы проведем вас через установку проекта FastAPI с помощью SqlAlchemy и PostgreSQL. Это включает создание модели, конфигурирование соединения с базой данных и определение асинхронных операций CRUD.
- Асинхронные операции CRUD: Изучение выполнения асинхронных операций CRUD, используя FastAPI и Async SqlAlchemy. Мы обсудим асинхронное создание, чтение, обновление и удаление записей в базе данных.
- Обработка связей: Изучение асинхронной обработки связей между таблицами базы данных с использованием Async SqlAlchemy. Мы обсудим подробно связи один-к-одному, один-ко-многим и многие-ко-многим.
- Обработка ошибок и проверка: Изучение методов обработки ошибок и проверки данных в FastAPI, гарантирующих целостность и безопасность ваших конечных точек API. Мы обсудим проверку входа, ответы об ошибках и обработку исключений.
Продолжить чтение "Освоение операций FastAPI CRUD с помощью Async SqlAlchemy и PostgreSQL"
Пересказ статьи Andrea Gnemmi. PostgreSQL Create Database Options and Settings
Первое, что нужно сделать администратору базы данных на новом экземпляре РСУБД, - это создать базу данных. Давайте узнаем, как это делается в PostgreSQL, включая синтаксис, особенности и отличия от других РСУБД.
Здесь будут рассмотрены все особенности и варианты синтаксиса команды CREATE DATABASE в PostgreSQL.
CREATE DATABASE в PostgreSQL
Базовый синтаксис команды CREATE DATABASE весьма прост и незатейлив: напечатайте CREATE DATABASE и имя базы данных, это все. Однако при этом вы должны иметь необходимые привилегии как суперпользователь (superuser) или иметь разрешение CREATEDB.
Краткое отступление о суперпользователе: в PostgreSQL это роль, довольно близкая к sa в SQL Server, и суперпользователь postgres создается по умолчанию при установке PostgreSQL. Мы вернемся к этой теме, когда я напишу более подробную статью о ролях. Так или иначе, эта тема вкратце раскрыта в следующих двух статьях:
Продолжить чтение "Параметры и настройки создания базы данных в PostgreSQL"
Пересказ статьи Semab Tariq. PostgreSQL Internals Part 2: Understanding Page Structure
Это вторая статья
данной серии. В первой части мы рассмотрели кластеры баз данных и их физическую структуру.
Во второй части мы изучим внутреннюю структуру страницы в PostgreSQL. Первую часть вы можете найти
здесь.
Обзор макета страницы в PostgreSQL
При создании таблицы генерируется соответствующий файл данных. Внутри этого файла данные размещаются на страницах фиксированной длины, обычно 8-килобайтных, что принимается по умолчанию. Каждой странице присваивается последовательный номер, начиная с 0, который называется номером блока. PostgreSQL добавляет новую пустую страницу к концу файла, когда он заполняется. Тем самым увеличивается размер файла данных.
Продолжить чтение "PostgreSQL изнутри. Часть 2: понимание структуры страницы"
Пересказ статьи Dmitry Romanoff. PostgreSQL. How do you find potentially ineffective indexes?
В то время как индексы в PostgreSQL могут значительно улучшить производительность запросов, особенно для тяжелых операций чтения, они полезны не во всех ситуациях.
Наличие слишком большого числа индексов на таблице PostgreSQL может оказать негативное влияние на производительность базы данных и потребление ресурсов.
Следующий запрос поможет вам найти потенциально неэффективные индексы.
Продолжить чтение "PostgreSQL. Как обнаружить потенциально неэффективные индексы?"
