
Возможности функции Crosstab в Pandas для анализа и визуализации данных
Пересказ статьи R. Gupta. The Power of Crosstab Function in Pandas for Data Analysis and Visualization
Pandas является популярной библиотекой Python для анализа и манипуляции данными. Она предоставляет мощные инструменты для работы с табличными данными, включая такие структуры как ряды и фреймы данных, и функции для очистки, слияния и изменения формы данных.
Одним из наиболее полезных инструментов для анализа табличных данных в Pandas является функция crosstab(). Эта функция позволяет вам рассчитать таблицу частот двух и более переменных, которые суммируют разбросанные в данных значения и позволяют выявить связь между переменными. Перекрестная табуляция (или crosstab) является важным инструментом для анализа двух категориальных переменных в наборе данных. Она дает сводную таблицу распределения частот двух переменных, позволяя увидеть взаимосвязь между ними и идентифицировать любые шаблоны или тренды.
В этой статье мы исследуем возможности функции crosstab() для анализа и визуализации данных и рассмотрим примеры кода для иллюстрации ее использования.
Что такое таблица частот?
Прежде чем рассматривать функцию crosstab(), давайте сначала выясним, что такое таблица частот.
Таблица частот - это таблица, которая показывает распределение значений в наборе данных, путем подсчета числа вхождений каждого значения. Предположим, например, что наш набор данных представляет информацию о студентах, которая содержит пол и уровень образования. Таблица частот пола и уровня образования должна суммировать число студентов мужчин и женщин по каждой категории уровня образования.
Таблица частот может быть представлена в разных форматах, таких как таблица сопряженности, перекрестная таблица или сводная таблица, в зависимости от данных и целей анализа. В Pandas функция crosstab() предоставляет простой и гибкий способ для расчета таблицы частот двух или более переменных.
Основы использования функции crosstab
Вот типичное использование функции crosstab():
pd.crosstab(index, columns, values=None, rownames=None, colnames=None, aggfunc=None, margins=False, margins_name='All', dropna=True, normalize=False)Функция crosstab() принимает несколько параметров, которые управляют поведением и выводом функции:
- index: Последовательность или объект типа массива, который определяет строки таблицы частот. Этот параметр может быть именем отдельного столбца, списком имен столбцов или массивом значений.
- columns: Последовательность или объект типа массива, который определяет столбцы таблицы частот. Этот параметр может быть именем отдельного столбца, списком имен столбцов или массивом значений.
- values: Дополнительный параметр, который задает значения, которые должны агрегироваться в таблице частот. Этот параметр может быть именем отдельного столбца, списком имен
столбцов или массивом значений. Если не указан, функция будет подсчитывать число вхождений каждой комбинации значений в индексе и столбцах. - rownames: Дополнительный параметр, который задает имена строк в таблице частот. Этот параметр может быть отдельной строкой или списком строк.
- colnames: Дополнительный параметр, который задает имена столбцов в таблице частот. Этот параметр может быть отдельной строкой или списком строк.
- aggfunc: Дополнительный параметр, который задает функцию агрегации, которая должна применяться к значениям в таблице частот. Этот параметр может быть строкой или вызываемым объектом, который принимает последовательность значений и возвращает скалярное значение. Если отсутствует, функция будет подсчитывать число вхождений каждой комбинации значений в индексе или столбцах.
- margins: Дополнительный параметр, который определяет, нужно ли вычислять итоговые поля для строк и столбцов в таблице частот. Если параметр установлен в True, функция будет добавлять строку и столбец в таблицу, которые выводят суммарные итоги. Значением по умолчанию является False.
- dropna: Дополнительный параметр, который определяет, нужно ли удалять строки и столбцы, которые содержат отсутствующие значения (значения NaN) в таблице частот. Если параметр установлен в True, функция будет удалять строки и столбцы, которые содержат отсутствующие значения. Значением по умолчанию является True.
- normalize: Дополнительный параметр, который определяет, нужно ли нормализовать таблицу частот, делением значений на общий итог. Если параметр установлен в True, функция будет нормализовать таблицу делением каждого значения на сумму всех значений. По умолчанию используется False.
Теперь, когда мы понимаем назначение параметров функции crosstab(), давайте рассмотрим несколько примеров использования функции для анализа и визуализации.
Пример 1: создание простой перекрестной таблицы
Начнем с простого примера создания перекрестной таблицы двух переменных: пола и уровня образования. Мы будем использовать набор данных с информацией о студентах, содержащей пол, уровень образования и результаты теста.
import pandas as pd
# создаем тестовый набор данных
df = pd.DataFrame({
'gender': ['male', 'male', 'female', 'female', 'male', 'female', 'male', 'female'],
'education_level': ['high school', 'college', 'college', 'graduate', 'high school', 'graduate', 'college', 'graduate'],
'score': [75, 82, 88, 95, 69, 92, 78, 85]
})
# создаем перекрестную таблицу по полу и уровню образования
ct = pd.crosstab(df['gender'], df['education_level'])
print(ct)Вывод:
education_level college graduate high school
gender
female 1 3 0
male 2 0 2
В этом примере мы создали перекрестную таблицу по полу и уровню образования, передав столбец gender (пол) в качестве индекса, а столбец education_level (уровень образования) как столбцы функции crosstab(). Функция подсчитывает число вхождений каждой комбинации значений и возвращает таблицу, которая суммирует распределение студентов по полу и уровню образования.
Пример 2: агрегация значений в перекрестной таблице
Помимо подсчета числа вхождений каждой комбинации значений, функция crosstab() позволяет вам выполнять другие агрегации значений в таблице. Например, вы можете вычислить средний балл за тест для студентов в каждой комбинации пол - уровень образования.
# создает перекрестную таблицу по полу и уровню образования со средним баллом
ct_mean = pd.crosstab(df['gender'], df['education_level'],
values=df['score'], aggfunc='mean')
print(ct_mean)Вывод:
education_level college graduate high school
gender
female 88.0 90.666667 NaN
male 80.0 NaN 72.0
В этом примере мы добавили параметр values в функцию crosstab() для столбца score (баллы). Мы также добавили параметр aggfunc со значением 'mean', который подсчитывает средний балл студентов в каждой комбинации пол - уровень образования.
Пример 3: добавление итоговых строк и столбцов
Вы можете также добавить итоговую строку и столбец в перекрестную таблицу, установив параметр margins в True.
# создаем перекрестную таблицу по полу и уровню образования
# с итоговыми строкой и столбцом
import seaborn as sns
ct_margins = pd.crosstab(df['gender'], df['education_level'], margins=True)
sns.heatmap(ct_margins, cmap='coolwarm', annot=True)
print(ct_margins)Вывод:
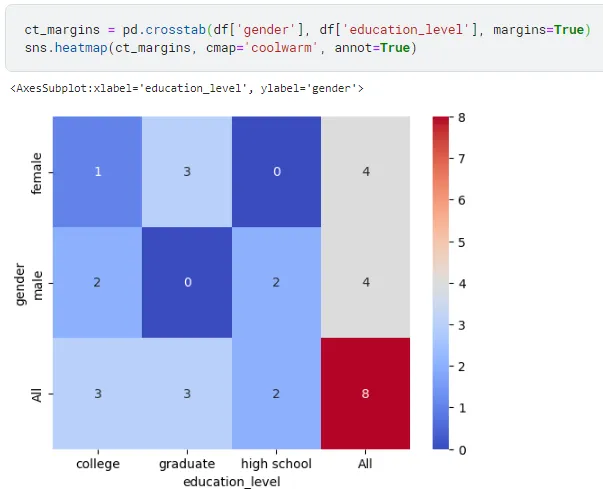
education_level college graduate high school All
gender
female 1 3 0 4
male 2 0 2 4
All 3 3 2 8
В этом примере мы добавили параметр margins в функцию crosstab() и установили его в значение True. Результирующая таблица включает итоговые строку и столбец, содержащие суммарные значения по каждой строке и столбцу, а также общее значение для всей таблицы.
Пример 4: нормализация перекрестной таблицы
Функция crosstab() позволяет вам также нормализовать таблицу делением значений на общий итог. Это может оказаться полезным для сравнения относительных частот различных комбинаций значений.
# создаем перекрестную таблицу по полу и уровню образования с нормализацией
ct_norm = pd.crosstab(df['gender'], df['education_level'], normalize=True,
margins=True)
print(ct_norm)Вывод:
education_level college graduate high school All
gender
female 0.125 0.375 0.00 0.5
male 0.250 0.000 0.25 0.5
All 0.375 0.375 0.25 1.0
В этом примере мы добавили параметр нормализации в функции crosstab() и установили его значение в True. Результирующая таблица показывает пропорции каждой комбинации пола и уровня образования, нормализованные к общему числу всех студентов.
Пример 5: визуализация перекрестной таблицы
Наконец, вы можете использовать функцию crosstab() для создания визуализации данных. Например, вы можете создать гистограмму с накоплением, чтобы показать распределение студентов по полу и уровню образования.
# создаем перекрестную таблицу по полу и уровню образования с визуализацией
ct_viz = pd.crosstab(df['gender'], df['education_level'])
ct_viz.plot(kind='bar', stacked=True)Вывод:
education_level college graduate high school
gender
female 1 3 0
male 2 0 2
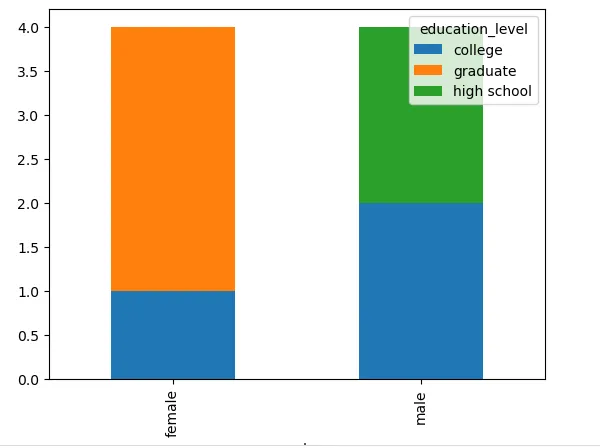
В этом примере мы использовали функцию plot() для перекрестной таблицы, чтобы создать гистограмму с накоплением, которая показывает распределение студентов по полу и уровню образования. Полученный график является полезной визуализацией, которая позволяет вам быстро сравнить соотношение студентов по разным категориям.
Пример 6: использование агрегатной функции в перекрестной таблице
Предположим, мы хотим вычислить средний балл студентов в зависимости от пола и уровня образования. Мы можем использовать функцию crosstab() с параметром aggfunc, установленным в np.mean для вычисления среднего балла для каждой комбинации пол - уровень образования.
import numpy as np
# создаем перекрестную таблицу по полу и уровню образования со средним баллом
ct_agg = pd.crosstab(df['gender'], df['education_level'], values=df['score'], aggfunc=np.mean)
print(ct_agg)Вывод:
education_level college graduate high school
gender
female 88.0 90.666667 NaN
male 80.0 NaN 72.0
В этом примере мы добавили параметр values в функцию crosstab() и установили его в значение df['score'], чтобы указать, что мы хотим применить функцию np.mean к значениям score. Результирующая таблица показывает средний балл для каждой комбинации пол - уровень образования.
Параметр aggfunc может также быть любой валидной агрегатной функцией, такой как sum, max, min, median, std, var и т.п. Это позволяет применять широкий диапазон статистических функций к значениям перекрестной таблицы, позволяя еще глубже вникнуть в соотношения между различными категориальными переменными.
Заключение
Функция crosstab() в pandas является мощным инструментом анализа и агрегации категориальных данных. Располагая различными параметрами и опциями, вы можете создать подробные и информативные таблицы, которые помогут понять связи между различными переменными ваших данных.
Ссылки по теме
1. Команды Pandas, которые я часто использую для анализа данных
2. Python для анализа и визуализации данных
3. Продвинутый Pandas: исчерпывающее руководство для энтузиастов данных
4. Практический анализ данных с Pandas
Обратные ссылки
Автор не разрешил комментировать эту запись
Комментарии
Показывать комментарии Как список | Древовидной структурой