
Столбцы с одинаковым упорядочиванием
Пересказ статьи Erik Darling. Columns That Share Ordering
Это следует иметь в виду, когда вам необходимо использовать сортировку большой таблицы.
Конечно, мы беспокоимся относительно ORDER BY по многим разумным причинам, особенно, когда не имеем индекса, поддерживающего упорядочение.
Сортировка данных требует памяти, и, в частности, операторы плана Sort могут запрашивать память.
Почему? Потому что вам необходимо сортировать все столбцы, которые вы выбираете по столбцу, по которому выполняется упорядочивание.
Сортируются не только столбцы, перечисленные в предложении ORDER BY , и, если вы выбираете SELECT *, вам придется сортировать все столбцы в * по всем столбцам, указанным в ORDER BY.
Допустим у нас есть таблица в базе данных. И, возможно, в ней есть столбец, который называется id.
Также предположим, что этот легендарный столбец id является первичным ключом и кластеризованным индексом.
Это означает, что вся наша таблица отсортирована по одному этому столбцу. Круто.
Пусть теперь в нашей таблице есть столбец типа date или datetime. И пусть он определяет, когда строка впервые была вставлена в таблицу.
Это может быть дата создания или дата заказа. Не важно.
А что важно? То, что этот столбец "id" и столбец "*Date" увеличивают свои значения одновременно. Это означает, что они имеют один и тот же порядок.
Может оказаться, что ваши запросы лучше сортировать по столбцу ключа кластеризованного индекса, а не по другому столбцу в таблице, который может не иметь полезного индекса для сортировки результатов вашего запроса.
Рассмотрим следующие два запроса:
Я понимаю, что они ужасно нереальные. Такого не бывает даже близко. Ну, хорошо.
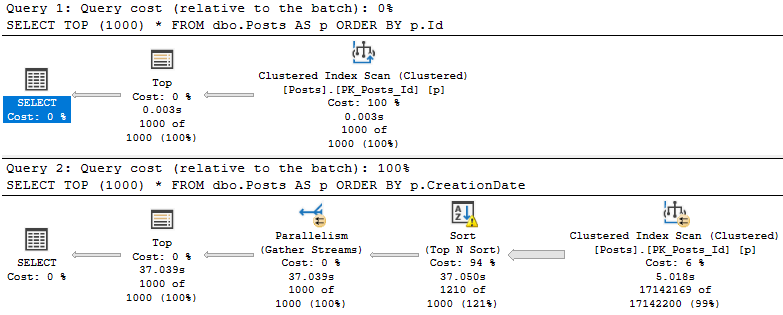
Хотя оба запроса предоставляют одни и те же данные в одном и том же порядке, запрос, который сортирует по столбцу CreationDate, занимает все время.
Причины очевидны.
Конечно, мы могли бы добавить соответствующий индекс. Просто добавить все индексы. Что не так?
Если ваше приложение позволяет пользователям, скажем, динамически фильтровать и упорядочивать данные по любым столбцам, вам потребуется создать множество индексов.
Почему? Потому что вам необходимо сортировать все столбцы, которые вы выбираете по столбцу, по которому выполняется упорядочивание.
Сортируются не только столбцы, перечисленные в предложении ORDER BY , и, если вы выбираете SELECT *, вам придется сортировать все столбцы в * по всем столбцам, указанным в ORDER BY.
Как вам это
Допустим у нас есть таблица в базе данных. И, возможно, в ней есть столбец, который называется id.
Также предположим, что этот легендарный столбец id является первичным ключом и кластеризованным индексом.
Это означает, что вся наша таблица отсортирована по одному этому столбцу. Круто.
Пусть теперь в нашей таблице есть столбец типа date или datetime. И пусть он определяет, когда строка впервые была вставлена в таблицу.
Это может быть дата создания или дата заказа. Не важно.
А что важно? То, что этот столбец "id" и столбец "*Date" увеличивают свои значения одновременно. Это означает, что они имеют один и тот же порядок.
Может оказаться, что ваши запросы лучше сортировать по столбцу ключа кластеризованного индекса, а не по другому столбцу в таблице, который может не иметь полезного индекса для сортировки результатов вашего запроса.
Избыточная сортировка
Рассмотрим следующие два запроса:
SELECT TOP (1000) *
FROM dbo.Posts AS p
ORDER BY p.Id;
SELECT TOP (1000) *
FROM dbo.Posts AS p
ORDER BY p.CreationDate;Я понимаю, что они ужасно нереальные. Такого не бывает даже близко. Ну, хорошо.
Хотя оба запроса предоставляют одни и те же данные в одном и том же порядке, запрос, который сортирует по столбцу CreationDate, занимает все время.
Причины очевидны.
Конечно, мы могли бы добавить соответствующий индекс. Просто добавить все индексы. Что не так?
Если ваше приложение позволяет пользователям, скажем, динамически фильтровать и упорядочивать данные по любым столбцам, вам потребуется создать множество индексов.
Обратные ссылки
Автор не разрешил комментировать эту запись
Комментарии
Показывать комментарии Как список | Древовидной структурой