
Ранжирование в Python и SQL
Пересказ статьи Nathan Rosidi. Ranking in Python and SQL
Мы обсуждали основы ранжирования в Python в нашем руководстве “Methods for Ranking in Pandas”, где рассматривались наиболее употребимые параметры функции ранжирования в Pandas. В частности, мы изучали различные методы ранжирования, которые имеют решающее значение в борьбе с родственными значениями. Помимо методов ранжирования функция ранжирования в Pandas обладает и другими параметрами, которые позволяют выполнить дальнейшую настройку и уточнение способа определения рангов. Понимание этих параметров важно при работе с наборами данных, которые требуют более таких сложных методов ранжирования, как процентильное ранжирование или работа с недостающими данными.
В этой статье мы рассмотрим эти параметры, чтобы подготовить вас к более эффективному и точному решению задач ранжирования. Мы также продемонстрируем применение некоторых методов ранжирования в SQL, которые являются обязательными навыками для аналитиков и специалистов по данным, особенно в организациях, которые используют SQL в качестве основного языка хранения и поиска данных.
Прочитав эту статью, вы получите исчерпывающее понимание методов ранжирования как в Python, так и в SQL, что придаст вам уверенности при решении задач, связанных с ранжированием и анализом наборов данных.
Параметры функции ранжирования
Функция Pandas rank() имеет несколько параметров, которые позволят настроить ранжирование на основе вашего набора данных. Эти параметры включают:
- pct: для возвращения процентильных рейтингов
- na_option: для управления обработкой NULL-значений при ранжировании
- axis: для рангов строк или столбцов
- numeric_only: для ранжирования числовых или нечисловых столбцов
pandas.DataFrame.rank
DataFrame.rank(axis=0, method='average', numeric_only=false, na_option='keep', ascending=True, pct=False)pct = False
Знаете ли вы, что в Pandas вы можете получить процентильное ранжирование, а не ранжирование целочисленное? По умолчанию метод .rank() устанавливает 'pct' в значение False и возвращает целочисленное ранжирование. Однако при установке в значение True метод .rank() вычисляет процентные ранги, которые нормализуются в диапазоне от 0 до 1.
Процентное ранжирование полезно, если вы хотите сравнить рейтинги различных столбцов вне зависимости от их фактических значений. Это дает стандартизованный способ измерения производительности или статуса человека по сравнению с остальной частью группы. Именно поэтому процентные рейтинги обычно используются в области образования или здравоохранения.
Итак, что точно представляет собой процентное ранжирование и как оно вычисляется?
Что такое процентильное ранжирование?
- Процентное отношение значений в распределении, которые меньше или равны заданному значению или имеют наименьший ранг
Фактически, процентильное ранжирование говорит о проценте значений в распределении, которые меньше или равны заданному значению или имеют наименьший ранг. Например, если студент получил 80 баллов из 100 на тесте и распределение баллов по классу таково, что 60% студентов получили менее 80 баллов, то процентильный рейтинг баллов студента составляет 60%.
Давайте рассмотрим пример вопроса от Генеральной Ассамблеи.
Найдите 80-й процентиль часов обучения. Вывести значение часов обучения в указанном процентиле.
Таблица: sat_scores
Ссылка на задание.
Мы должны найти 80-й процентиль часов обучения. Другими словами, "80% студентов, обучавшихся менее х часов?"
Для решения этой задачи мы будем использовать функцию ранжирования, установив pct в значение True. Для сравнения позвольте мне показать вам результаты с опцией ранжирования по умолчанию.
# Импорт библиотек
import pandas as pd
# Начало кода
sat_scores.head()
sat_scores['percentile_rank'] = sat_scores['hrs_studied'].rank(axis = 0 , pct = True)
sat_scores['rank'] = sat_scores['hrs_studied'].rank(axis = 0)
sat_scores[['hrs_studied', 'rank', 'percentile_rank']].sort_values(by='percentile_rank', ascending=False)
Как видно, максимальное значение (т.е. 200 часов) получает процентиль 1, поскольку 100 значений ранжируется ниже него (в то время как минимальное значение равно 0, поскольку это уже самый низкий ранг).
В случае одинаковых значений ранжирование определяется средним процентилем для группы совпадающих значений.
na_option = 'keep'
Параметр na_option позволяет управлять обработкой NULL-значений при выполнении ранжирования. По умолчанию na_option установлен в 'keep', означающее, что для этих записей ранг не возвращается. Однако вы можете установить na_option в значение ‘bottom’ или ‘top’, что присваивает либо наименьший, либо наибольший ранг этим строкам.
# Импорт библиотек
import pandas as pd
import numpy as np
# Начало кода
sat_scores.head()
sat_scores['rank_default'] = sat_scores['hrs_studied'].rank()
sat_scores['rank_natop'] = sat_scores['hrs_studied'].rank(na_option='top')
sat_scores['rank_nabottom'] = sat_scores['hrs_studied'].rank(na_option='bottom')
sat_scores.sort_values(by='rank_natop') 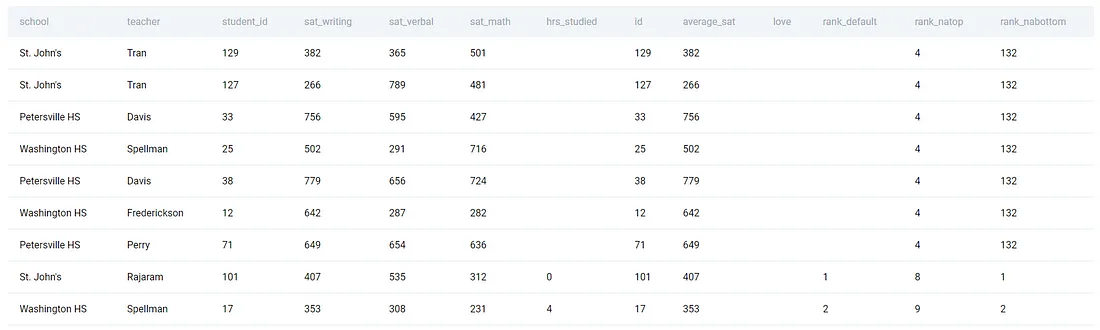
Видно, что опция по умолчанию оставляет ранг NULL, но мы можем легко изменить это, присвоением максимального или минимального ранга.
axis = 0
Параметр определяет что ранжировать - строки или столбцы. Большую часть времени мы ранжируем строки, и опция по умолчанию предполагает это поведение. Однако, если вы когда-либо столкнетесь с другим типом наборов данных, типа временных рядов KPI, вам может понадобиться ранжировать столбцы, чтобы определить временные тренды для каждого KPI (представленного столбцом). Для этого установите axis в значение 1, а не 0.
numeric_only = True
Как и ранее, для numeric_only опция по умолчанию установлена для обычного случая использования, которым является ранжирование на основе числовых значений. Однако если вы хотите ранжировать как по числовым, так и нечисловым значениям, например, упорядочить записи по имени, вы можете сделать это, установив параметр в значение False.
Ранжирование в SQL и Python
Аналитики и специалисты по данным обычно должны владеть SQL и Python, поэтому теперь, когда вы познакомились с различными способами ранжирования в Python, давайте рассмотрим эквивалентные функции в SQL!
Процентильный рейтинг

В SQL вы можете получить его с помощью оконной функции percent_rank(). Почему бы не попробовать ее на том же самом примере?
Найдите 80-й процентиль часов обучения. Вывести значение часов обучения в указанном процентиле.
SELECT *,
percent_rank() OVER (ORDER BY hrs_studied) as study_percentile
from sat_scores
Order by study_percentile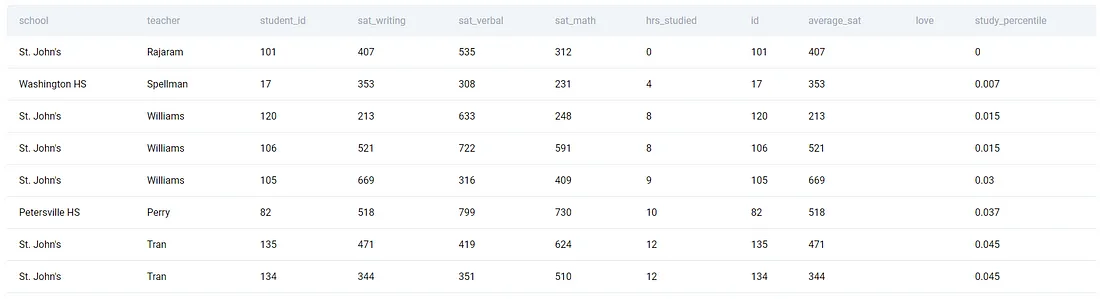
По умолчанию NULL остаются внизу и, следовательно, получают наивысший рейтинг (т.е. близкий к 1). Это не согласуется с функцией ранжирования в Python, где NULL-значения не получают никакого ранга по умолчанию, если не изменить параметр na_option.
Чтобы ранжировать NULL, вы можете указать это в предложении ORDER BY. Например:
SELECT *,
percent_rank() OVER (ORDER BY hrs_studied NULLS FIRST) as study_percentile
from sat_scores
Order by study_percentile Ранжирование (method='min')

Используя набор данных гостей от Airbnb, мы будем ранжировать гостей по возрасту, где самые старшие получают высший рейтинг
Ранжируйте гостей по возрасту. Вывести Id гостя и соответствующий ему ранг. Упорядочить записи по возрасту в убывающем порядке.
Таблица: airbnb_guests
Ссылка на задание
Напомню, что в Python мы использовали функцию .rank() и устанавливали ascending (порядок сортировки) в значение False.
airbnb_guests['rank'] = airbnb_guests['age'].rank(method='min', ascending = False)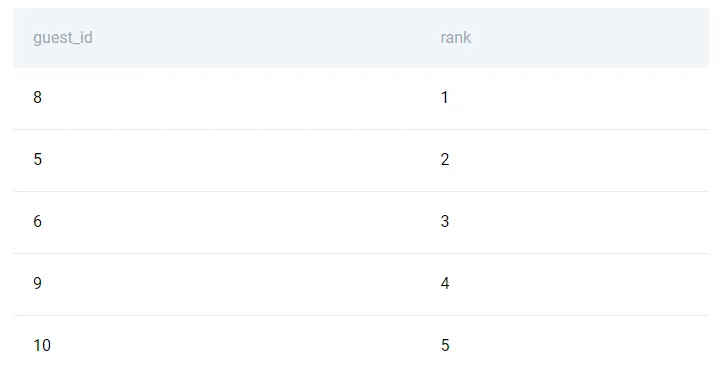
В SQL мы будем использовать оконную функцию rank и укажем, что возраст должен быть упорядочен по убыванию.
SELECT
guest_id,
RANK() OVER(ORDER BY age DESC)
FROM airbnb_guests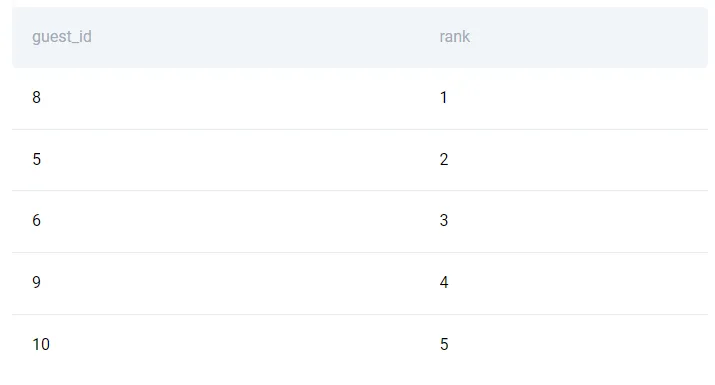
Посмотрите на одинаковые значения и заметьте, что оконная функция RANK() в SQL использует метод минимума для ранжирования групп с одинаковыми значениями. Метод минимума дает минимально возможный ранг одинаковым значениям. Например, гости в возрасте 27 находятся на позициях 6 и 7. Из-за совпадения для обоих гостей используется ранг 6.
Ранжирование (method='dense')
В Python мы используем функцию rank() с методом method='dense', чтобы получить ранжирование без зазоров в значениях ранга. В SQL мы используем оконную функцию dense_rank(), для получения тех же результатов.

Давайте решим следующую задачу на SQL.
Ранжировать хозяев по кроватям
Присвоить каждому хозяину ранг в зависимости от числа предоставляемых кроватей. Хозяин с наибольшим числом кроватей должен получить ранг 1, а хозяин с наименьшим числом должен ранжироваться последним. Хозяева с одинаковым числом кроватей должны иметь одинаковый ранг, но не должно быть зазоров между значениями рангов. Хозяин может также владеть несколькими объектами недвижимости. Вывести ID хозяина, число кроватей и ранг от наивысшего к наименьшему.
Таблица: airbnb_apartments
Ссылка на задание
Для начала давайте получим число кроватей для каждого хозяина.
host_id,
sum(n_beds) as number_of_beds
FROM airbnb_apartments
GROUP BY host_id
А теперь добавим ранжирование:
SELECT
host_id,
sum(n_beds) as number_of_beds,
DENSE_RANK() OVER(ORDER BY sum(n_beds) DESC) as rank
FROM airbnb_apartments
GROUP BY host_id
ORDER BY number_of_beds desc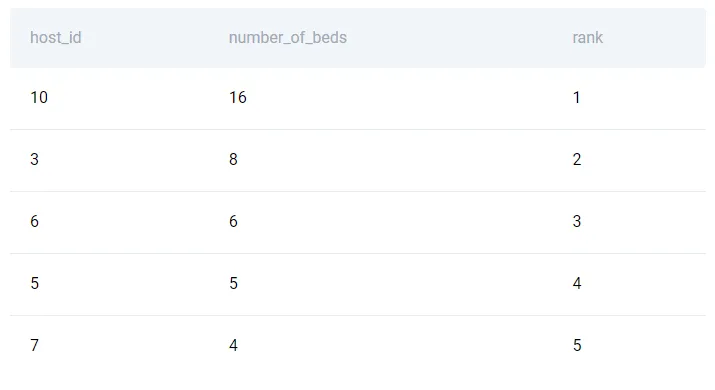
Это дает требуемый нам метод ранжирования, который не имеет зазоров в значениях ранга.
Ранжирование (method='first')
В Python мы используем функцию rank() с method=’first’ для назначения уникального ранга каждой записи. В SQL мы используем оконную функцию row_number() для получения аналогичных результатов.

Рейтинг активности
Определить рейтинг активности электронной почты для каждого пользователя. Рейтинг активности электронной почты определяется по общему числу отправленных сообщений. Пользователь с наивысшим числом сообщений получит ранг 1 и т.д. Вывести пользователя, общее число сообщений и рейтинг активности. Упорядочить записи по общему числу сообщений в убывающем порядке. Пользователей с одинаковым числом сообщений отсортировать в алфавитном порядке. В вашем рейтинге вернуть уникальное значение (т.е. уникальный ранг), даже если несколько пользователей имеют одинаковое число почтовых сообщений. При неоднозначности использовать алфавитный порядок имени пользователей.
Таблица: google_gmail_emails
Сначала давайте получим общее число почтовых сообщений от каждого пользователя.
SELECT from_user,
count(*) as total_emails
FROM google_gmail_emails
GROUP BY from_userЗатем будем использовать это в качестве основы для нашего ранжирования. Мы можем использовать row_number() в SQL для создания уникальных рейтингов.
SELECT from_user,
count(*) as total_emails,
row_number() OVER ( order by count(*) desc, from_user asc)
FROM google_gmail_emails
GROUP BY from_user
order by 2 DESC, 1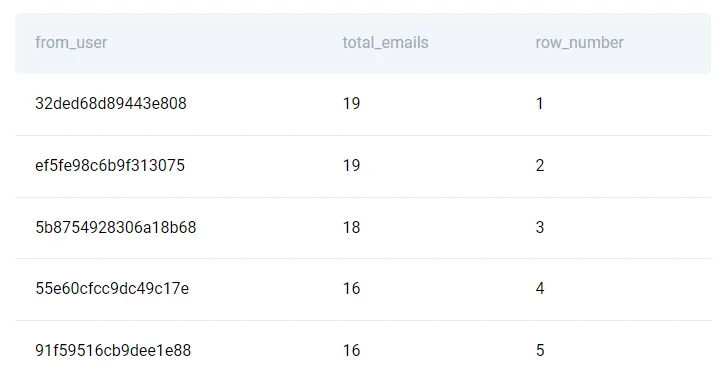
Теперь вы имеете методы ранжирования в Python и SQL.
Заключение
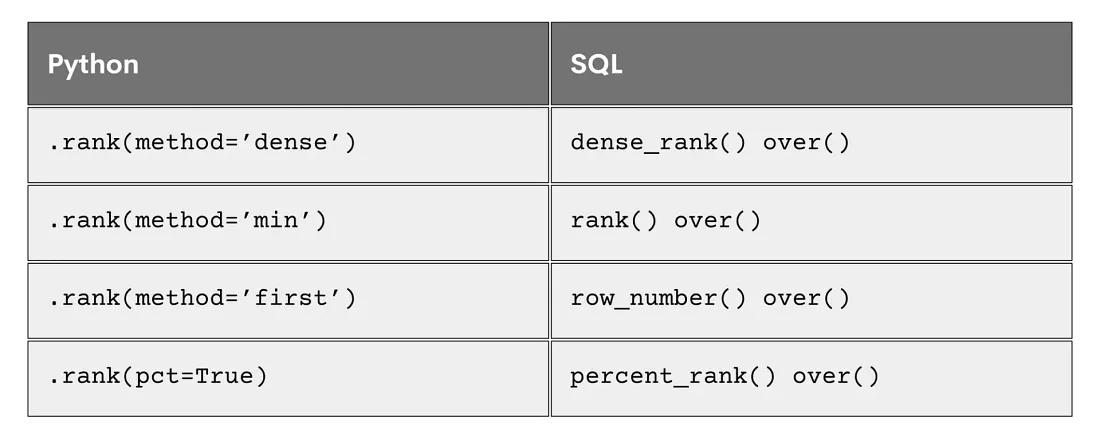
В этой статье мы рассмотрели другие параметры в функции rank в Python, такие как pct, na_option, axis и numeric_only. Мы также показали некоторые методы ранжирования в Python и их эквиваленты в SQL. Вот справочная таблица:
Совет!
Если вам необходимо изменить способ ранжирования NULL-значений, задайте это в предложении ORDER BY. Например, RANK() OVER(ORDER BY col NULLS FIRST).
Ранжирование помогает выявить шаблоны и тренды в наборах данных, поэтому это важный инструмент для аналитиков данных.
Ссылки по теме
1. Функции ранжирования
2. Обзор функции медианы на SQL
Обратные ссылки
Автор не разрешил комментировать эту запись
Комментарии
Показывать комментарии Как список | Древовидной структурой