
Работа с текстовыми данными в Pandas
Пересказ статьи Tirendaz AI. Working with Text Data in Pandas
Реальные наборы данных состоят не только из чисел, они также включают текст. При анализе данных важно уметь работать с этим текстом.
В этой статье я собираюсь поговорить на следующие темы:
- Как использовать методы работы со строками в Pandas?
- Как использовать регулярные выражения в Pandas?
- Примеры работы с набором данных IMDb
Давайте начнем!
Python является популярным языком манипуляции данными, поскольку в нем легко работать с текстом. Он имеет набор встроенных методов, которые вы можете применять к строкам. В можете также быстро использовать эти методы в Pandas.
Например, давайте переведем слово hello в верхний регистр.

В Pandas вам потребуется набрать код str, чтобы использовать методы для строковых или регулярных выражений. Чтобы продемонстрировать это, давайте импортируем Pandas и Numpy.

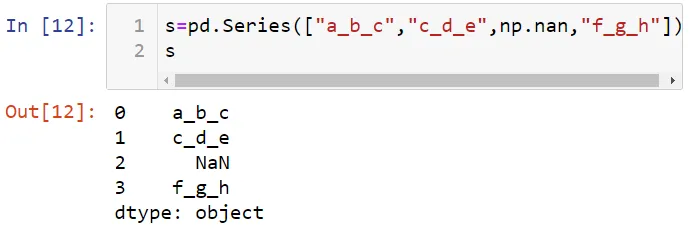
Теперь давайте создадим данные.

Давайте сделаем заглавной первые буквы в значениях этих данных. Но сначала преобразуем эти данные в ряд.

Вы можете использовать атрибут str для применения методов работы со строками для рядов и индексных объектов. Делаем заглавной первую букву в данных.
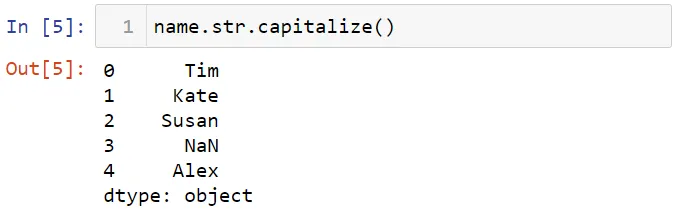
Вы можете также сделать все буквы строчными.
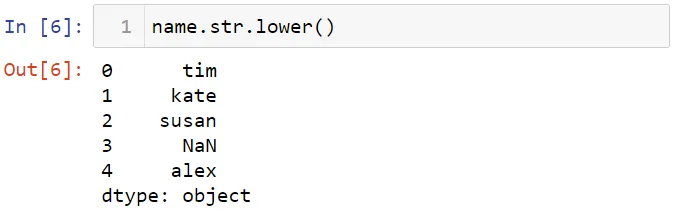
Вы можете найти длину текста с помощью метода len.
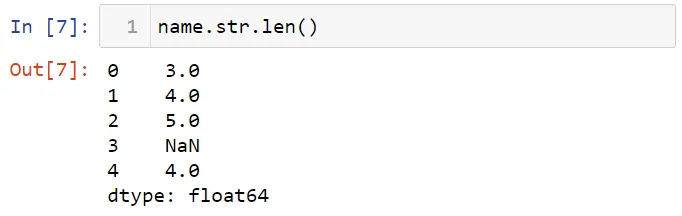
Можно найти имена, которые начинаются с буквы "a", с помощью метода startswith.
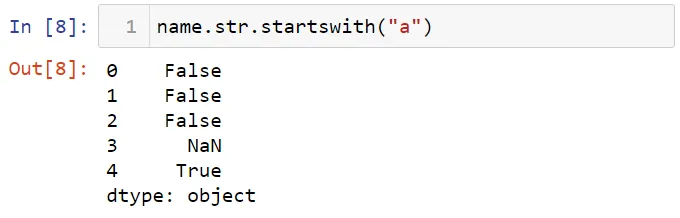
Вы можете применить методы работы со строками к индексным объектам. Для демонстрации давайте создадим фрейм данных.
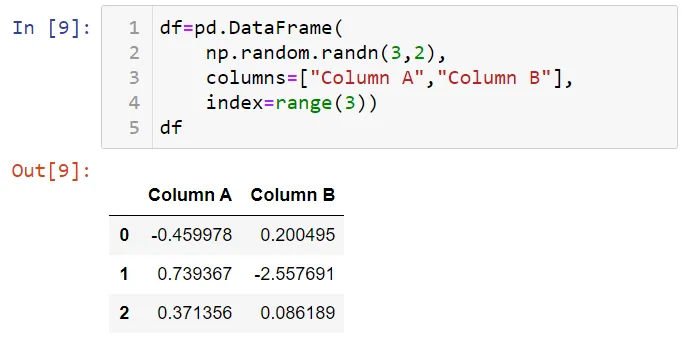
Взглянем на столбцы набора данных.

df.columns является индексным объектом. Вы можете использовать атрибут str для этого объекта. Например, переведем имена столбцов в нижний регистр и заменим пробелы символом _.

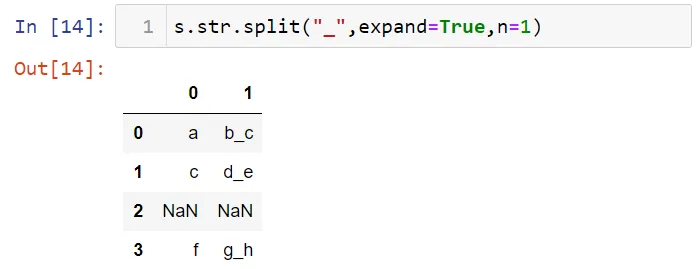
Вы можете использовать для рядов такие методы, как split. Вот данные для демонстрации:
Давайте выполним разбиение на буквы по нижнему подчеркиванию. Я будут использовать символ [] для выбора первого индекса.

Вы можете преобразовать отдельные значения во фрейме данных, используя параметр expand=True. Также вы можете ограничить процесс split с помощью параметра n. Вот так:
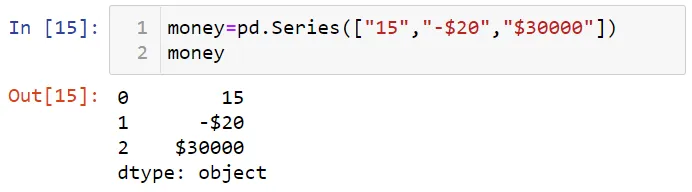
Вы можете также использовать регулярные выражения в Pandas. Для демонстрации давайте создадим пример финансовых данных.
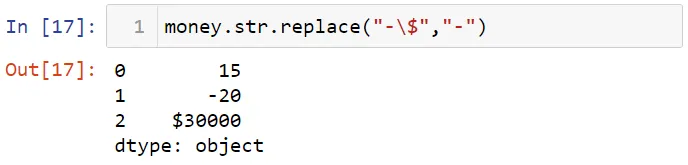
Давайте удалим символ доллара.
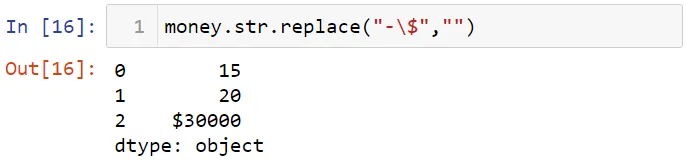
Заметьте, что символ $ является метасимволом, и он имеет особый смысл в регулярных выражениях. Для удаления этого символа, который является метасимволом, вам потребуется использовать экранирующий символ обратного слэша. Давайте заменим "-$" на "-".
Я собираюсь привести примеры методов работы со строками, используя реальный набор данных. Набор данных представляет собой фильмы с наивысшим рейтингом на IMDb. Сначала давайте импортируем набор данных.

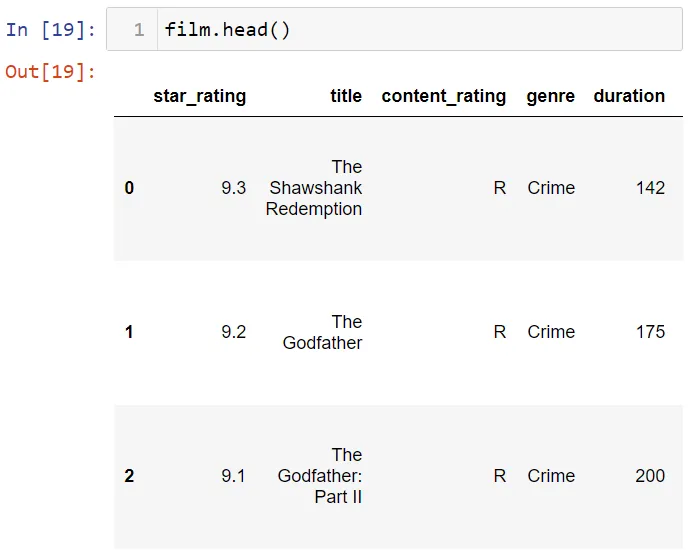
Получить этот набор данных можно отсюда. Вот первые строки этого набора данных.
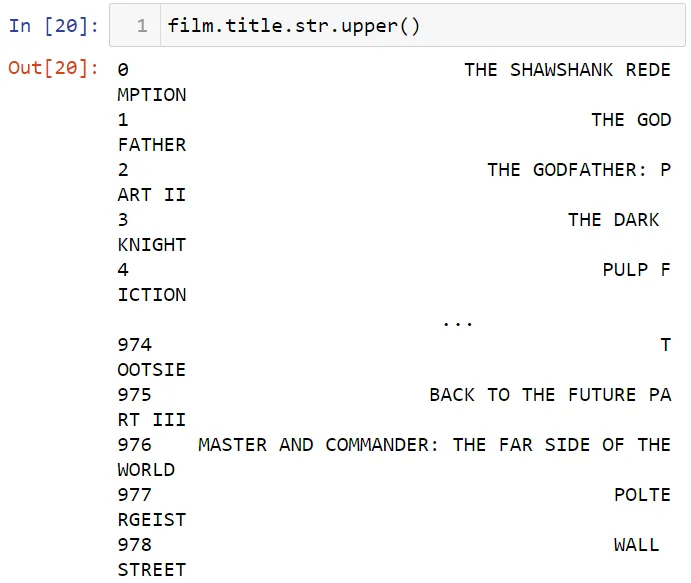
Давайте преобразуем строки столбца title в верхний регистр, используя метод upper.
Столбцы в наборе данных были индексными объектами. Сделаем первую букву в этих именах заглавной с помощью метода capitalize.

Взглянем на набор данных с помощью метода head.
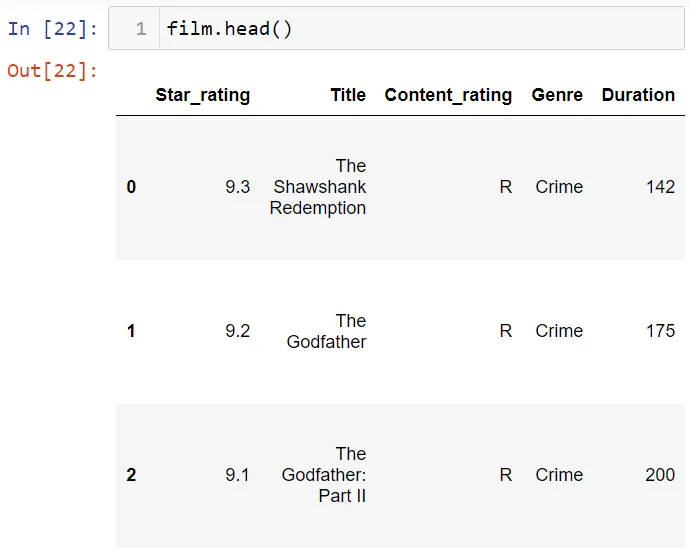
Вы можете использовать метод contains для проверки наличия текста в наборе данных. Например, поищем имя Brad Pitt в списке актеров.
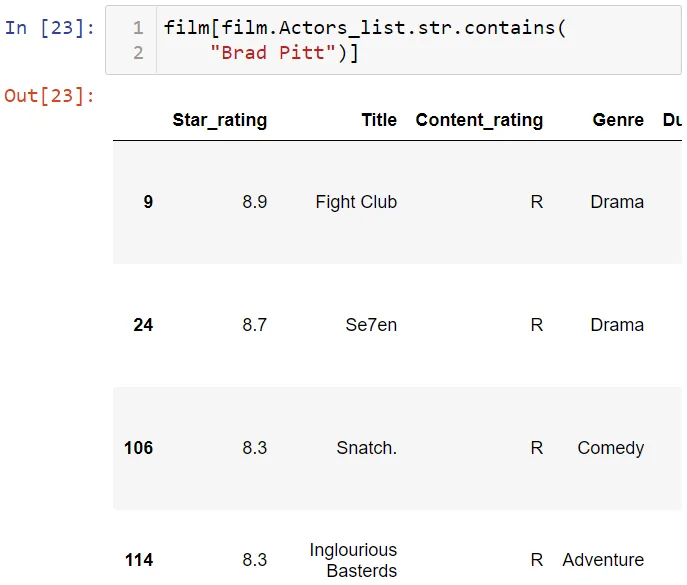
Вы можете использовать метод replace для удаления символа. Например, удалим квадратные скобки из списка актеров.
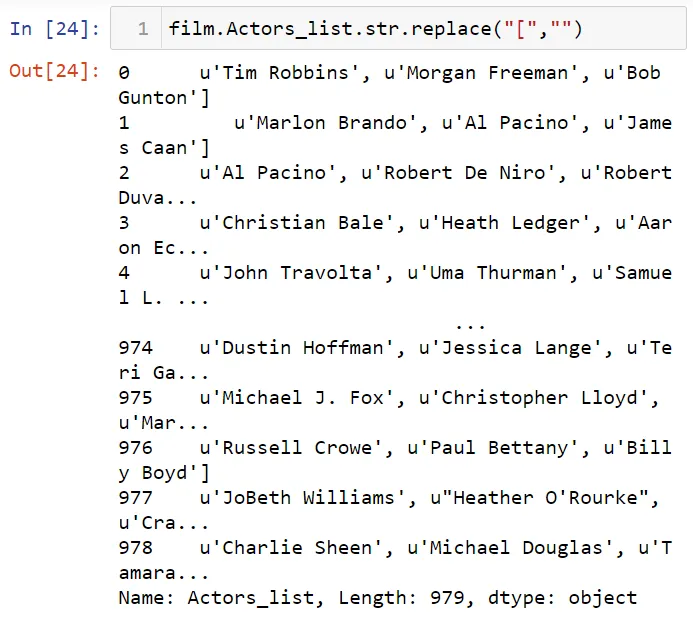
Вот так можно удалить скобки:
Ссылки по теме
1. От SQL к Pandas: руководство по переходу
2. Команды Pandas, которые я часто использую для анализа данных
Как использовать методы работы со строками в Pandas?
Python является популярным языком манипуляции данными, поскольку в нем легко работать с текстом. Он имеет набор встроенных методов, которые вы можете применять к строкам. В можете также быстро использовать эти методы в Pandas.
Например, давайте переведем слово hello в верхний регистр.
В Pandas вам потребуется набрать код str, чтобы использовать методы для строковых или регулярных выражений. Чтобы продемонстрировать это, давайте импортируем Pandas и Numpy.
Теперь давайте создадим данные.
Давайте сделаем заглавной первые буквы в значениях этих данных. Но сначала преобразуем эти данные в ряд.
Вы можете использовать атрибут str для применения методов работы со строками для рядов и индексных объектов. Делаем заглавной первую букву в данных.
Вы можете также сделать все буквы строчными.
Вы можете найти длину текста с помощью метода len.
Можно найти имена, которые начинаются с буквы "a", с помощью метода startswith.
Вы можете применить методы работы со строками к индексным объектам. Для демонстрации давайте создадим фрейм данных.
Взглянем на столбцы набора данных.
df.columns является индексным объектом. Вы можете использовать атрибут str для этого объекта. Например, переведем имена столбцов в нижний регистр и заменим пробелы символом _.
Вы можете использовать для рядов такие методы, как split. Вот данные для демонстрации:
Давайте выполним разбиение на буквы по нижнему подчеркиванию. Я будут использовать символ [] для выбора первого индекса.
Вы можете преобразовать отдельные значения во фрейме данных, используя параметр expand=True. Также вы можете ограничить процесс split с помощью параметра n. Вот так:
Как использовать регулярные выражения в Pandas?
Вы можете также использовать регулярные выражения в Pandas. Для демонстрации давайте создадим пример финансовых данных.
Давайте удалим символ доллара.
Заметьте, что символ $ является метасимволом, и он имеет особый смысл в регулярных выражениях. Для удаления этого символа, который является метасимволом, вам потребуется использовать экранирующий символ обратного слэша. Давайте заменим "-$" на "-".
Практика с набором данных IMDb
Я собираюсь привести примеры методов работы со строками, используя реальный набор данных. Набор данных представляет собой фильмы с наивысшим рейтингом на IMDb. Сначала давайте импортируем набор данных.
Получить этот набор данных можно отсюда. Вот первые строки этого набора данных.
Давайте преобразуем строки столбца title в верхний регистр, используя метод upper.
Столбцы в наборе данных были индексными объектами. Сделаем первую букву в этих именах заглавной с помощью метода capitalize.
Взглянем на набор данных с помощью метода head.
Вы можете использовать метод contains для проверки наличия текста в наборе данных. Например, поищем имя Brad Pitt в списке актеров.
Вы можете использовать метод replace для удаления символа. Например, удалим квадратные скобки из списка актеров.
Вот так можно удалить скобки:
Ссылки по теме
1. От SQL к Pandas: руководство по переходу
2. Команды Pandas, которые я часто использую для анализа данных
Обратные ссылки
Автор не разрешил комментировать эту запись
Комментарии
Показывать комментарии Как список | Древовидной структурой