
Причины скачков производительности запроса в SQL Server
Пересказ статьи Aaron Bertrand. Reasons for SQL Server Query Performance Fluctuations
Производительность запроса может испытывать скачки с течением времени, и это не обязательно обусловлено изменениями в самом запросе (или в коде приложения, которое его вызывает). Пользователи часто спрашивают, почему запрос внезапно стал работать медленнее, хотя они ничего не меняли в приложении, а данные не изменялись резко. В этой статье мы укажем на несколько причин - их существует много - по которым запрос мог замедлиться сегодня по сравнению с тем, что было 10 минут назад, две недели назад, или прошлым летом.
Прежде чем вникать в возможные причины скачков производительности, давайте сделаем обзор того, что происходит в SQL Server при обработке запросов.
Когда вы посылаете запрос в первый раз, движок производит ("компилирует") план выполнения, подобный шаблону или диаграмме потоков для обеспечения выполнения запроса. Ниже показана высокоуровневая и весьма упрощенная диаграмма потоков:
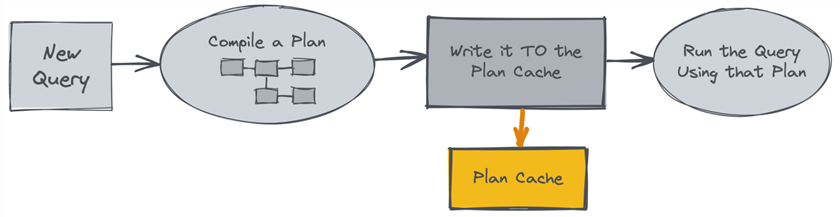
Это не всегда наиболее оптимальный план из возможных; оптимизатор старается минимизировать время, которое он тратит на поиск плана, который кажется "достаточно хорошим" для удовлетворения данного запроса. План содержит такую информацию, как таблицы и индексы, которые он будет использовать, какой метод он будет использовать для выполнения соединения, как он будет фильтровать и сортировать результаты и т.п. Он принимает эти решения на базе оценки стоимости; на которую влияют предположения о количестве имеющихся строк (согласно статистике), количестве строк, удовлетворяющих критериям запроса, количестве доступной памяти и других факторах. План используется для выполнения запроса и сохраняется в кэше планов. Это хранилище не является постоянным, план будет оставаться в кэше в соответствии с формулой, учитывающей доступную память, сложность и самое последнее использование (LRU) - если это дешевый план и/или недостаточно часто используемый, он будет вытеснен из кэша, чтобы освободить место для более сложных и/или более "популярных" планов. Весь кэш планов может быть очищен по другим причинам, в том числе, из-за перезапуска службы, сбоя или определенных изменений конфигурации или команд DBCC.
Назначение сохранения планов - обеспечение повторного их использования при последовательных выполнениях одного и того же запроса, избегая тем самым накладных расходов на повторную компиляцию. Вот другая упрощенная диаграмма потоков:
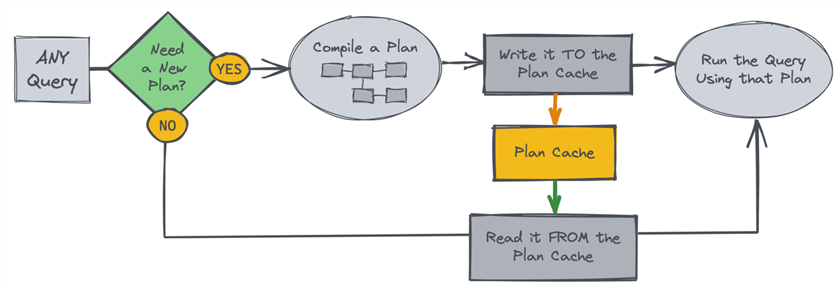
Обратной стороной медали является то, что повторное использование того же плана, скомпилированного для одного набора параметров, может выполняться хуже для другого набора значений параметров (или если данные радикально изменились при тех же значениях параметров). Это происходит потому, что один и тот же подход может не работать одинаково хорошо при различных объемах данных. Для многих шаблонов запросов, которые мы обычно используем на Stack Overflow, стоимость компиляции часто аннулируется влиянием использования неоптимального плана в неправильном сценарии.
Представим себе запрос, который запрашивает все публикации (и комментарии к этим публикациям конкретного пользователя). Если план компилируется первый раз для совершенно нового пользователя (который имеет только один пост), а затем он используется для меня (свыше 4000 постов), он может быть оптимизирован для очень небольшого числа чтений, что ведет к неоптимальной обработке для большого набора данных. В обратном сценарии он может быть оптимизирован для очень большого выделения памяти, которая будет использована впустую и может повредить параллельно выполняющимся запросам, если большинство выполнений предназначаются для "небольшой рыбки". В действительности большинство запросов не имеют идеальный подходящий для всех размеров план выполнения, я будут в большинстве случаев иметь "достаточно хороший" план, который не будет впадать в крайности.
(Исторически мы называем эту проблему "parameter sniffing"- прослушивание параметра - но Microsoft пытался склонить нас к использованию термина "parameter sensitivity" - чувствительность к параметру.)
В этом контексте следует выделить два главных момента:
Запрос, который SQL Server встречал ранее, может получить план выполнения, отличающийся от плана, использованного в последний раз. Хотя сравнение прошлого и нынешнего плана может потенциально объяснить, почему разные планы имеют разную производительность, но то, почему эти планы отличаются, бывает не столь очевидно. Обычно это отслеживается изменением статистики и/или отличающимися значениями параметров, изменившимися с момента последней компиляции. Эта перекомпиляция может произойти, если:
Даже если план уже существует и его выбирает SQL Server для использования, или план не существует, но тот же самый план компилируется опять, запрос может выполняться хуже, чем раньше, по разным причинам (и сразу многие из этих факторов могут также играть роль при создании отличающегося плана):
Когда запрос начинает плохо работать, поскольку начинает использовать неоптимальный план, главной целью должно быть восстановление прежней производительности. Одним из способов является выбрасывание плохого плана из кэша, убедиться в актуальности статистики и надеяться, что в следующий раз будет скомпилирован лучший план. К сожалению, такой тип немедленного решения проблемы может помешать анализу, поскольку вы естественно теряете все доказательства. Становится трудно определить, какой из вышеприведенных факторов мог привести к регрессии. Вы могли бы принять к рассмотрению навязывание плана из хранилища запросов для запросов, которые постоянно проявляют эти симптомы. Потенциально некоторые из дополнительных возможностей SQL Server 2022, связанных с производительностью, будут автоматически применяться для некоторых из этих сценариев.
Другие сценарии, такие как блокирование (необходимая часть OLTP-систем), обычно быстро разрешаются. Иногда они обусловлены единичными человеческими ошибками, на которых мы всегда учимся.
Если данные просто достигают порогового значения ("переломные моменты"), вряд ли стоит ожидать, что SQL Server сгенерирует достаточно эффективный план для данного запроса и существующих индексов. Мы можем провести анализ индексов и/или улучшение запроса в подобных случаях. Для очень сложных запросов (например, с большим количеством CTE), одно из потенциальных решений - это помочь оптимизатору, материализовав некоторые из этих CTE во временные таблицы.
Другим общим случаем является наличие соединения один-ко-многим (например, клиенты и заказы) и применение DISTINCT или группировки к левой стороне, когда фактически нет необходимости в выводе правой стороны соединения. В этом случае было бы лучше использовать EXISTS и убрать DISTINCT.
Ссылки по теме
1. Внутри оптимизатора: оценка стоимости плана
2. 5 причин, которые следует рассмотреть при падении производительности запроса
3. Почему Parameter Sniffing не всегда плохо (хотя обычно так и есть)
4. Значение уровня совместимости базы данных в SQL Server
5. Перекомпиляция запроса SQL и её влияние на производительность
6. Адаптивная обработка запроса в SQL Server 2017
7. Общие табличные выражения (CTE)
Это не всегда наиболее оптимальный план из возможных; оптимизатор старается минимизировать время, которое он тратит на поиск плана, который кажется "достаточно хорошим" для удовлетворения данного запроса. План содержит такую информацию, как таблицы и индексы, которые он будет использовать, какой метод он будет использовать для выполнения соединения, как он будет фильтровать и сортировать результаты и т.п. Он принимает эти решения на базе оценки стоимости; на которую влияют предположения о количестве имеющихся строк (согласно статистике), количестве строк, удовлетворяющих критериям запроса, количестве доступной памяти и других факторах. План используется для выполнения запроса и сохраняется в кэше планов. Это хранилище не является постоянным, план будет оставаться в кэше в соответствии с формулой, учитывающей доступную память, сложность и самое последнее использование (LRU) - если это дешевый план и/или недостаточно часто используемый, он будет вытеснен из кэша, чтобы освободить место для более сложных и/или более "популярных" планов. Весь кэш планов может быть очищен по другим причинам, в том числе, из-за перезапуска службы, сбоя или определенных изменений конфигурации или команд DBCC.
Назначение сохранения планов - обеспечение повторного их использования при последовательных выполнениях одного и того же запроса, избегая тем самым накладных расходов на повторную компиляцию. Вот другая упрощенная диаграмма потоков:
Обратной стороной медали является то, что повторное использование того же плана, скомпилированного для одного набора параметров, может выполняться хуже для другого набора значений параметров (или если данные радикально изменились при тех же значениях параметров). Это происходит потому, что один и тот же подход может не работать одинаково хорошо при различных объемах данных. Для многих шаблонов запросов, которые мы обычно используем на Stack Overflow, стоимость компиляции часто аннулируется влиянием использования неоптимального плана в неправильном сценарии.
Представим себе запрос, который запрашивает все публикации (и комментарии к этим публикациям конкретного пользователя). Если план компилируется первый раз для совершенно нового пользователя (который имеет только один пост), а затем он используется для меня (свыше 4000 постов), он может быть оптимизирован для очень небольшого числа чтений, что ведет к неоптимальной обработке для большого набора данных. В обратном сценарии он может быть оптимизирован для очень большого выделения памяти, которая будет использована впустую и может повредить параллельно выполняющимся запросам, если большинство выполнений предназначаются для "небольшой рыбки". В действительности большинство запросов не имеют идеальный подходящий для всех размеров план выполнения, я будут в большинстве случаев иметь "достаточно хороший" план, который не будет впадать в крайности.
(Исторически мы называем эту проблему "parameter sniffing"- прослушивание параметра - но Microsoft пытался склонить нас к использованию термина "parameter sensitivity" - чувствительность к параметру.)
В этом контексте следует выделить два главных момента:
- Запрос становится медленней после построения нового, отличающегося плана.
- Запрос становится медленней даже при повторном использовании (или пересоздании) того же самого плана.
Новый, отличающийся план
Запрос, который SQL Server встречал ранее, может получить план выполнения, отличающийся от плана, использованного в последний раз. Хотя сравнение прошлого и нынешнего плана может потенциально объяснить, почему разные планы имеют разную производительность, но то, почему эти планы отличаются, бывает не столь очевидно. Обычно это отслеживается изменением статистики и/или отличающимися значениями параметров, изменившимися с момента последней компиляции. Эта перекомпиляция может произойти, если:
- В запросе явно используется хинт OPTION (RECOMPILE).
- Изменение таблицы/индекса/статистики сделало недействительными существующие планы.
- Новый план мог отличаться в силу чувствительности к параметру, но также из-за нерепрезентативной статистической выборки (представьте миграцию или операции, которые вставляют, обновляют или удаляют большое число строк).
- План мог быть удален из кэша в результате работы алгоритма или под влиянием других описанных выше причин.
- В типичных сценариях маловероятной причиной является изменение конфигурации типа Оптимизации передаваемых непосредственно запросов, поскольку эти изменения не происходят часто. Но если вы выполняете апгрейд базы данных, изменяете уровень совместимости, включаете функции уровня базы данных или применяете патч SQL Server, это может спровоцировать шквал новых планов.
- Соединения имеют различные схемы по умолчанию или различные сессионные установки.
- Текст запроса изменился, даже если код приложения - нет - возможно, некоторые другие изменения привели к другой структуре запроса, такие как флаг функции или изменения в ORM или API, которые помогают генерировать возможный запрос.
- Запрос, который не может быть правильно параметризован считается совершенно другим, требуя своего собственного плана, даже если разница лишь в литерале - такая, как строка даты, встроенная в запрос. В некоторых случаях каждая вариация запроса может спровоцировать новую компиляцию.
Тот же самый план
Даже если план уже существует и его выбирает SQL Server для использования, или план не существует, но тот же самый план компилируется опять, запрос может выполняться хуже, чем раньше, по разным причинам (и сразу многие из этих факторов могут также играть роль при создании отличающегося плана):
- Имеется высокая конкуренция, ведущая к более жесткому соревнованию за разделяемые ресурсы, такие как память. Малое выделение памяти может привести к тому, что ранее работающие целиком в памяти запросы теперь сбрасывают данные на более медленные диски, или нехватка памяти может привести запрос в состояние ожидания, когда память освободится.
- Имеет место блокирование из-за агрессивных или широких блокировок или возможных конфликтов при большом изменении данных или высокой цикличности.
- Запрос выполняется более часто, чем ожидалось - даже быстрые запросы могут вызвать проблемы при масштабировании.
- Теперь имеется просто больше данных (либо которые запрос возвращает для конкретного набора значений параметров, либо всех и должен прочитать все) - определенные пороговые значения (или проблема "восходящего ключа") могут сделать предыдущий выбор менее оптимальными, и они не обязательно непосредственно коррелируют с фактическим числом строк.
- Данные могут больше не находиться в буферном пуле подобно планам; данные также находятся в памяти, пока они не устаревают. Это означает, что в следующий раз, когда данные будут затребованы, они сначала должны быть считаны с диска в память, и только затем запрос может получить к ним доступ.
- План использует адаптивное соединение или различные цикличные механизмы обратной связи типа обратной связи по выделению памяти, которые могут стать причиной появления различных операций или доступности различных ресурсов для разных выполнений одного и того же плана.
- Компиляция не бесплатна. Даже генерация одного и того же плана снова и снова может способствовать ухудшению времени выполнения для сложных запросов, поэтому принудительная генерация с помощью OPTION (RECOMPILE) не всегда является идеальным решением. Более сложные запросы (много соединений, CTE, большие списки IN() и т.д.) приводят к увеличению времени компиляции, но даже для простых запросов это может усиливаться в «горячих путях», когда запросы выполняются часто и лишние 5 мс могут убить сайт. Влияние таких "горячих" запросов, занимающих даже немного больше времени по различным причинам, больше сказывается на стороне веб-приложений, чем на стороне базы данных.
Смягчение последствий
Когда запрос начинает плохо работать, поскольку начинает использовать неоптимальный план, главной целью должно быть восстановление прежней производительности. Одним из способов является выбрасывание плохого плана из кэша, убедиться в актуальности статистики и надеяться, что в следующий раз будет скомпилирован лучший план. К сожалению, такой тип немедленного решения проблемы может помешать анализу, поскольку вы естественно теряете все доказательства. Становится трудно определить, какой из вышеприведенных факторов мог привести к регрессии. Вы могли бы принять к рассмотрению навязывание плана из хранилища запросов для запросов, которые постоянно проявляют эти симптомы. Потенциально некоторые из дополнительных возможностей SQL Server 2022, связанных с производительностью, будут автоматически применяться для некоторых из этих сценариев.
Другие сценарии, такие как блокирование (необходимая часть OLTP-систем), обычно быстро разрешаются. Иногда они обусловлены единичными человеческими ошибками, на которых мы всегда учимся.
Если данные просто достигают порогового значения ("переломные моменты"), вряд ли стоит ожидать, что SQL Server сгенерирует достаточно эффективный план для данного запроса и существующих индексов. Мы можем провести анализ индексов и/или улучшение запроса в подобных случаях. Для очень сложных запросов (например, с большим количеством CTE), одно из потенциальных решений - это помочь оптимизатору, материализовав некоторые из этих CTE во временные таблицы.
Другим общим случаем является наличие соединения один-ко-многим (например, клиенты и заказы) и применение DISTINCT или группировки к левой стороне, когда фактически нет необходимости в выводе правой стороны соединения. В этом случае было бы лучше использовать EXISTS и убрать DISTINCT.
Ссылки по теме
1. Внутри оптимизатора: оценка стоимости плана
2. 5 причин, которые следует рассмотреть при падении производительности запроса
3. Почему Parameter Sniffing не всегда плохо (хотя обычно так и есть)
4. Значение уровня совместимости базы данных в SQL Server
5. Перекомпиляция запроса SQL и её влияние на производительность
6. Адаптивная обработка запроса в SQL Server 2017
7. Общие табличные выражения (CTE)
Обратные ссылки
Автор не разрешил комментировать эту запись
Комментарии
Показывать комментарии Как список | Древовидной структурой