
Понимание индекса SQL: ключ к быстрому выполнению запросов
Пересказ статьи Kishan Modasiya. Understanding SQL Index: The Key to Faster Query Execution
Индекс - это очень важная тема в SQL. И очень большая для того, чтобы рассмотреть ее в одной статье. Здесь я дам краткий обзор понятия индекса, что это такое и почему он так необходим, рассмотрю типы индексов и то, как индексы помогают оптимизировать производительность запросов на ряде примеров. Я буду выдерживать эту статью понятной для новичков и не углубляться в тему. Итак, начнем.
Индексы - это молчаливые партнеры в SQL, работающие за сценой, чтобы запросы пели.
Что такое индекс в SQL и для чего он нужен?
Структура данных, которая ускоряет операции извлечения данных. Непонятно, так ведь! Поясним на примере библиотеки.
Скажем, вы находитесь в огромной библиотеке и вам нужно найти книгу на конкретную тему, например, "Машинное обучение". Без помощи вам пришлось бы просмотреть каждую книгу в библиотеке, что заняло бы массу времени.
В библиотеке имеется каталог, в котором перечислены все книги и их аннотации. Этот каталог действует как индекс; с помощью каталога вы найдете нужную книгу значительно быстрее. Вам просто нужно найти "Машинное обучение" в каталоге и узнать, какие книги относятся к этой теме, и где они лежат. Итак, теперь вам проще найти конкретную книгу в библиотеке по сравнению с просмотром всей библиотеки.
Проще говоря, индекс работает как каталог для таблицы базы данных. Когда в таблице находится много информации, то нахождение конкретной информации займет много времени. Но если у вас есть индекс на столбце таблицы, то это подобно созданию каталога для этого столбца.
В качестве примера рассмотрим таблицу с информацией о пользователях, которая содержит имя пользователя, возраст, адрес и т.д. Теперь вы хотите получить информацию о пользователе с именем "Mike", и у вас нет индекса на этом столбце. Тогда база данных должна пройти по всем именам по одному, пока не обнаружит "Mike". Но если мы создадим индекс на столбце "name", что эквивалентно созданию каталога имен в алфавитном порядке. И теперь, когда мы имеем индекс на столбце "name", при поиске "Mike" найти его будет легче, т.к. имена уже отсортированы в алфавитном порядке.
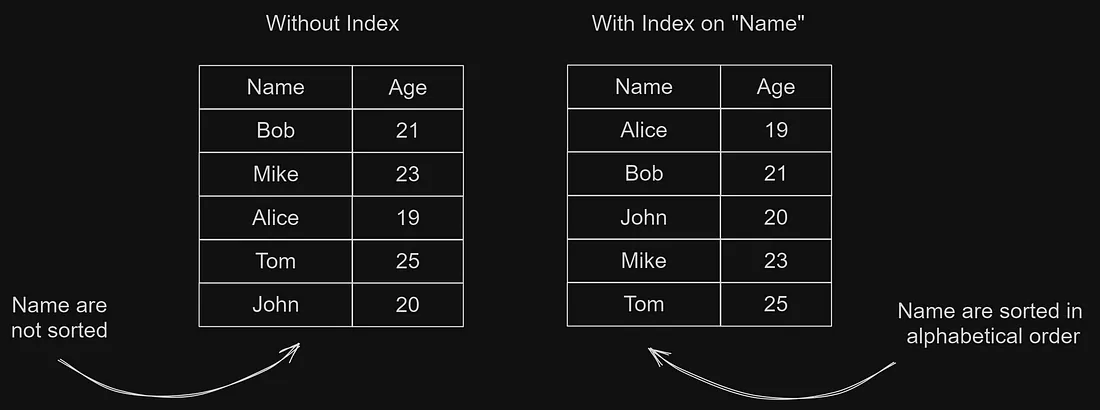
Таблица с индексом и без него
Итак, теперь мы имеем базовое понимание что такое индекс и зачем он нужен. Давайте перейдем к типам индексов.
Типы индексов
Имеется несколько типов индексов. Я не буду слишком глубоко в них погружаться, но дам их краткий обзор с синтаксисом, относящимся к Microsoft SQL Server.
- Кластеризованный индекс
Он определяет физический порядок записей в таблице. Таблица может иметь только один кластеризованный индекс, и он часто создается (автоматически) на столбце первичного ключа.
Когда таблица имеет кластеризованный индекс, строки данных хранятся на диске в том же самом порядке, что и в кластеризованном индексе.
CREATE CLUSTERED INDEX имя_индекса
ON имя_таблицы (столбец1, столбец2, ...); - Некластеризованный индекс
Некластеризованный индекс является отдельной от таблицы структурой данных и содержит копию выбранных столбцов в сортированном виде. Он позволяет быстрый доступ к данным на основе проиндексированных столбцов вне зависимости от физического порядка самих данных. Мы можем создать множество некластеризованных индексов на одной таблице.
CREATE NONCLUSTERED INDEX имя_индекса
ON имя_таблицы (столбец1, столбец2, ...);
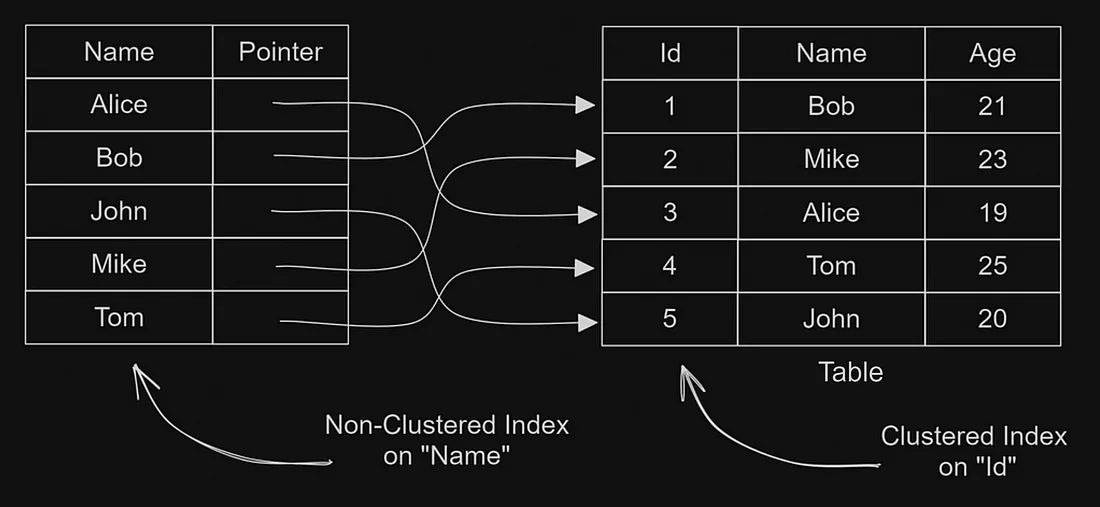
Кластеризованный и некластеризованный индекс - Уникальный индекс
Уникальный индекс обеспечивает соблюдение уникальности значений в столбце. Он часто используется на столбцах, представляющих первичные ключи или другие уникальные идентификаторы. Он гарантирует, что никакие две строки не будут иметь одинаковые значения в проиндексированном столбце.
CREATE UNIQUE INDEX имя_индекса
ON имя_столбца (столбец1, столбец2, ...); - Фильтрованный индекс / частичный индекс
Когда мы создаем индекс на подмножестве строк таблицы или строк с заданным условием, то он называется фильтрованным индексом. В некоторых базах данных фильтрованный индекс и частичный индекс имеют один и тот же смысл, но некоторые проводят незначительное отличие.
CREATE INDEX имя_индекса
ON имя таблицы (столбец1, столбец2, ...)
WHERE условие_фильтрации; - Покрывающий индекс
Когда индекс включает все столбцы, необходимые для выполнения запроса, он называется покрывающим индексом. Например, мы создали некластеризованный индекс на 3 столбцах, и мы запрашиваем только эти столбцы, тогда этот некластеризованный индекс называется покрывающим индексом. Покрывающий индекс делает ненужным доступ к индексируемой таблице. - Поколоночный индекс
Этот индекс используется в системе с поколоночным хранением данных. Как правило, он используется для запросов к большим таблицам в хранилищах данных. Этот индекс использует поколоночное хранение данных, а не построчное.
CREATE [ CLUSTERED | NONCLUSTERED ] COLUMNSTORE INDEX имя_индекса
ON имя_таблицы; - Пространственный индекс
Пространственный индекс позволяет проиндексировать пространственный столбец. Пространственный столбец - это столбец таблицы, который содержит данные пространственного типа, подобные фигуре или местности, географии.
CREATE SPATIAL INDEX имя_индекса
ON имя_таблицы (столбец_геометрии)
USING GEOMETRY_AUTO_GRID;
Как индекс улучшает производительность запроса?
Перейдем к основной части, оптимизации запросов с помощью индексов. Индекс помогает оптимизировать запрос для быстрого и эффективного получения данных из таблицы.
Здесь я использую Microsoft SQL Server и SSMS (SQL Server Management Studio) для выполнения запросов. Использовалась таблица с 5000000 строками данных о людях. (Загрузить выборку csv)
Сначала включим фактический план выполнения (нажмите Ctrl + M), чтобы увидеть план выполнения запроса, с помощью которого мы можем получить представление о том, как извлекаются данные.
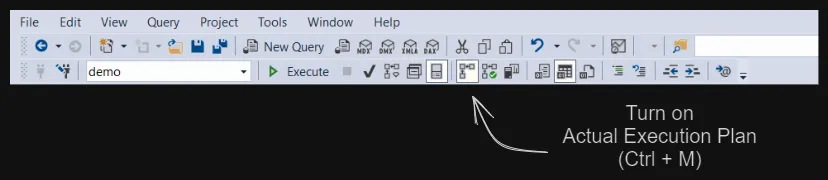
План выполнения в SSMS
План выполнения запроса: Последовательность, в которой осуществляется доступ к исходным таблицам. Методы, используемые для извлечения данных из каждой таблицы.
- Быстрое извлечение данных
Индекс помогает в быстром извлечении данных, позволяя ядру базы данных быстро находить конкретные строки, которые удовлетворяют критериям поиска запроса. Они служат как бы дорожной картой для ядра, направляя его к релевантным данным, уменьшая при этом необходимость в затратном полном сканировании таблицы. - Избегайте сканирования таблицы
table scan - это сканирование всей таблицы в поисках данных, отвечающих конкретному условию. Хотя сканирование иногда необходимо, оно неэффективно и медленно, особенно при работе с большими наборами данных. Это ухудшает производительность, увеличивает использование ЦП, дискового ввода/вывода и памяти.
Рассмотрим пример:
Имеется таблица people со столбцами Id, First_Name, Last_Name, Sex, Email, Date_of_Birth и Job_Title.
Без индекса на Id:
SELECT * FROM people
WHERE Id = 1430;
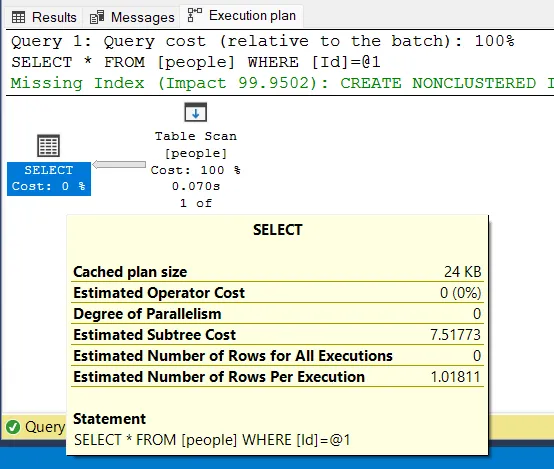
План выполнения со сканированием таблицы
Используется Table Scan, и базе данных может потребоваться просканировать всю таблицу people, чтобы найти конкретную строку.
С индексом (кластеризованный индекс на Id):
CREATE CLUSTERED INDEX PK_people ON people(Id);
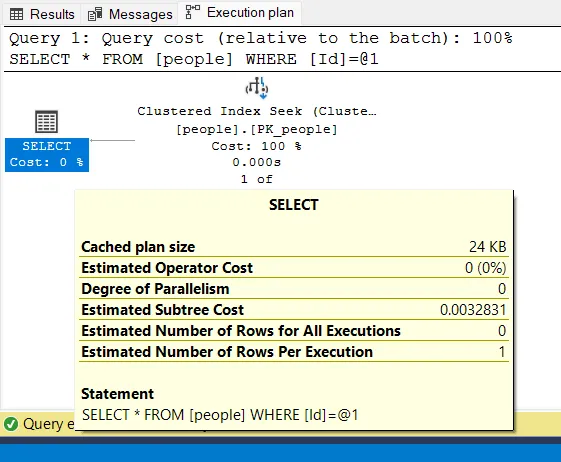
План выполнения с поиском в индексе
Теперь мы можем увидеть, что используется Index Seek, который значительно лучше, чем сканирование таблицы. Теперь база данных не должна сканировать всю таблицу, а может непосредственно получить доступ к записям с помощью индекса, который мы создали.
subtree cost (стоимость поддерева) представляет предварительную стоимость плана. чем меньше стоимость поддерева, тем меньше ожидается потребность в вычислительных ресурсах.
В нашем случае стоимость поддерева составляет 7.51773 при отсутствии индекса и 0.0032831, когда имеется индекс. - Уменьшайте число дисковых операций ввода/вавода
Дисковые операции ввода/вывода оказывают непосредственное влияние на производительность запросов, особенно когда дисковая активность слишком велика или неэффективна. Процесс считывания или записи данных на диск обозначается как disk I/O. Неэффективность дисковых операций ввода/вывода может вызвать медленное выполнение запросов.
Правильно спроектированные индексы могут уменьшить необходимость в полном сканировании таблиц и минимизировать ввод/вывод.
Рассмотрим на примере, как индекс может уменьшить число дисковых операций ввода/вывода.
Выполните этот запрос и проверьте статистику ввода/вывода:
(Сначала нажмите F4 или перейдите View -> Properties Windows, чтобы открыть свойства)
SELECT Id, First_Name, Last_Name, Email
FROM people
WHERE First_Name LIKE 'Ki%';
Для поверки статистики ввода вывода:
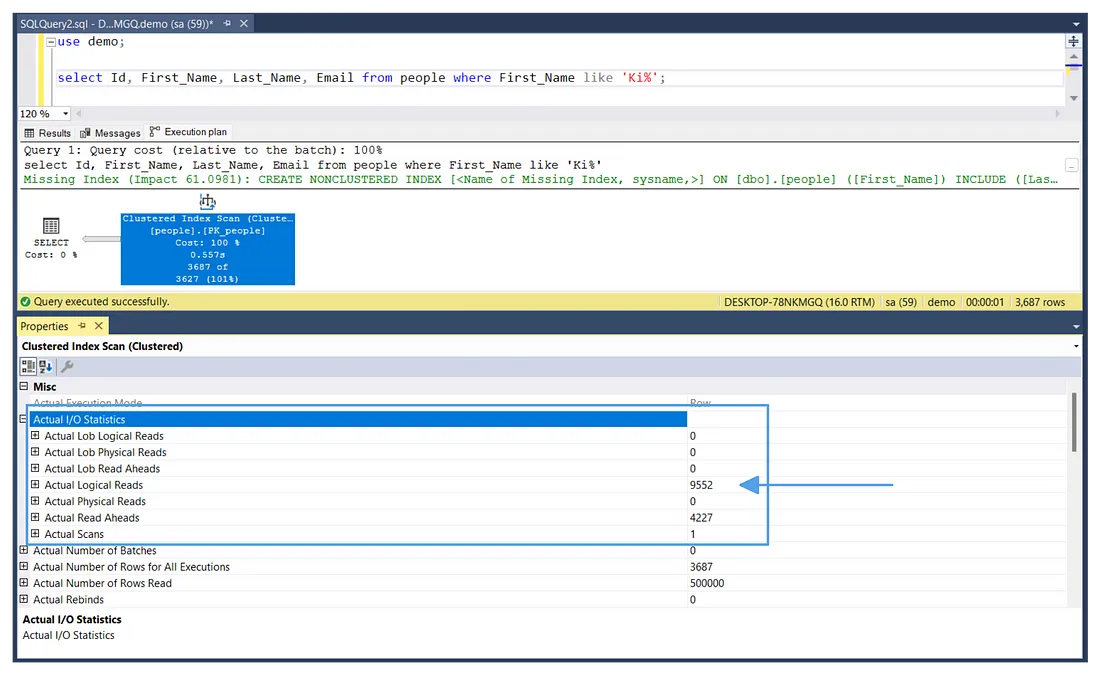
Фактическая статистика ввода/вывода до индекса
Теперь мы можем увидеть фактическую статистику ввода/вывода, действительно число логических чтений равно 9552.
Теперь создадим индекс:
CREATE INDEX IX_first_name ON people (First_Name)
INCLUDE (Id, Last_Name, Email);
Снова выполним тот же запрос и проверим статистику ввода/вывода:
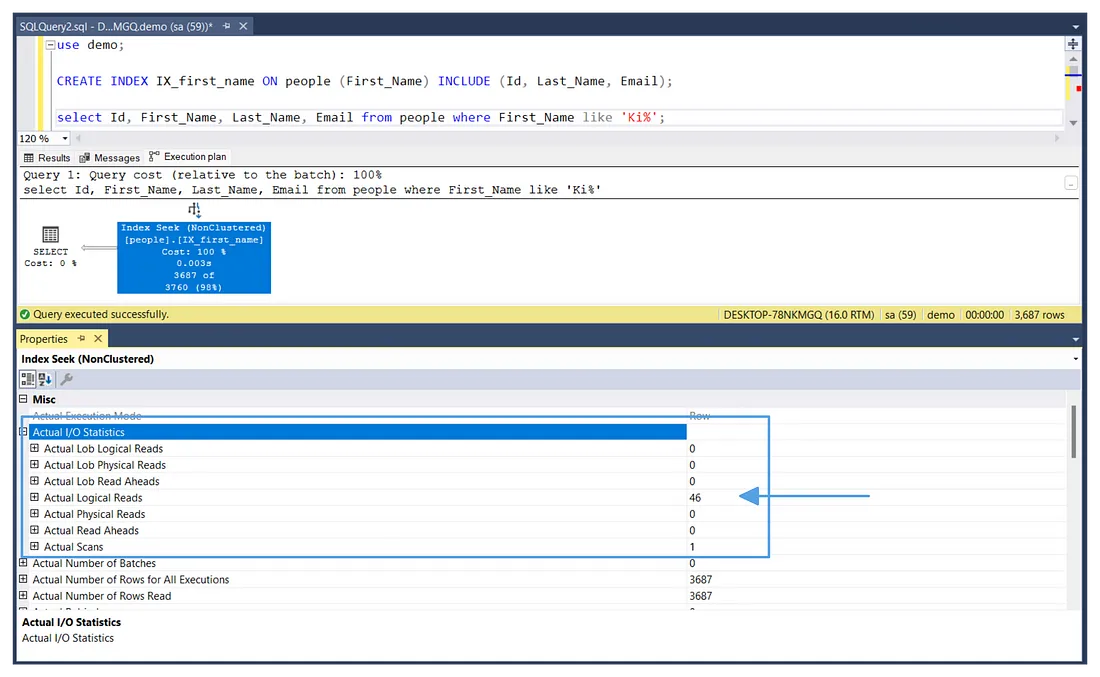
Фактическая статистика ввода/вывода после создания индекса
Видно, что фактическое число логических чтений уменьшилось до 46, демонстрируя как использование индекса может уменьшить число чтений с диска. - Сортировка, группировка, соединение
Индексы на столбцах сортировки (например, ORDER BY) позволяют ядру извлекать данные в желаемом порядке. Вместо выполнения отдельного шага сортировки ядро может эффективно извлекать данные, используя отсортированную структуру индекса.
Индексы на столбцах, используемых в операциях группировки (например, GROUP BY) помогают ядру сгруппировать вместе схожие данные. Операции агрегации и суммирования ускоряются, когда ядро может сканировать индекс в порядке группируемых значений.
Индексы помогают в операциях соединения, позволяя ядру базы данных быстро находить сочетающиеся строки в таблицах, сокращая необходимость полного сканирования таблиц и улучшая производительность запросов.
Будьте осторожны
При работе с индексами важно быть осторожным и принимать обоснованные решения, чтобы избежать потенциальных рисков и обеспечить оптимальную производительность базы данных.
Имейте в виду следующие важные факторы:
- Не создавайте слишком много индексов: Переиндексированная таблица может увеличить требования к хранилищу, замедлить операции модификации данных и усложнить обслуживание индексов. Создавайте индексы, если только они необходимы для увеличения производительности запросов.
- Обслуживайте индексы: Следует регулярно мониторить и обслуживать индексы, чтобы избежать фрагментации, которая со временем может снизить производительность. Если индексы фрагментированы, рассмотрите необходимость их перестройки или реорганизации.
- Статистика индекса: Поддерживайте актуальность статистики индексов, чтобы оптимизатор запросов мог принять точное решение относительно выбора плана выполнения.
- Неиспользуемый индекс: Регулярно пересматривайте использование индексов. Если индекс не используется никаким запросом, лучше его удалить.
Когда следует избегать индексов?
Хотя индексы являются полезным инструментом для улучшения производительности запросов, при некоторых обстоятельствах может быть лучше избегать их или использовать в редких случаях. Вот некоторые ситуации, когда, возможно, лучше избегать их или использовать минимально:
- Часто обновляемая таблица: Индексы могут вызвать значительную нагрузку при частом выполнении операций вставки, обновления или удаления в таблице. Обслуживание индексов требуется для каждой операции модификации, что может ухудшить производительность записи.
- Небольшие таблицы: Для таких таблиц не требуется индекс, поскольку ядро базы данных может быстро их сканировать.
- Столбцы с низким кардинальным числом: Проиндексированные столбцы с незначительным числом различных значений могут не обеспечить значительный прирост производительности и будут фактически увеличивать стоимость хранения и обслуживания.
- Пакетная загрузка данных: Часто более эффективным оказывается удаление индексов перед загрузкой большого количества данных в пакете с последующим их воссозданием. Обслуживание индекса при загрузке данных может вызвать задержку выполнения.
Заключение
Вкратце, индексы являются незаменимыми объектами в SQL. Они облегчают быструю и эффективную сортировку огромных объемов данных. Индексы дают нашим приложениям новый уровень оперативности, улучшая операции сортировки, группировки и объединения, а также производительность запросов.
Ссылки по теме
1. Фильтрованные индексы
2. Как думать подобно SQL Server: добавить некластеризованный индекс
3. Давайте спроектируем индекс вместе
4. Проектирование индекса в базах данных и оптимизация: некоторые рекомендации
5. Покрывающие индексы SQL Server с ключевыми и неключевыми столбцами для повышения производительности
6. Кардинальное число (мощность множества)
7. Все, что вам нужно знать о поколоночных индексах, в одной статье
8. Удалить сразу все избыточные индексы в каждой базе данных
Обратные ссылки
Автор не разрешил комментировать эту запись
Комментарии
Показывать комментарии Как список | Древовидной структурой