
Параллелизм базы данных в PostgreSQL
Пересказ статьи Mohan Saraswatipura. Database Concurrency in PostgreSQL
Управление параллелизмом является важным аспектом в системах баз данных, которые имеют дело с множеством параллельно выполняющихся транзакций. В PostgreSQL применяются различные методы для обеспечения параллельного доступа к базе данных при поддержке согласованного состояния данных с использованием свойств атомарности и изоляции ACID (атомарность, согласованность, изоляция и длительность).
Методы управления параллелизмом
В системах управления базами данных широко применяются три метода управления параллелизмом - пессимистичная, оптимистичная блокировки и многоверсионное управление параллелизмом (MVCC). Этот раздел будет введением в перечисленные методы.
Пессимистичная блокировка
Этот метод управления параллелизмом используется в системах баз данных для обеспечения параллельного доступа к разделяемым данным. Это осторожный подход, предполагающий, что конфликты между транзакциями весьма вероятны, и предотвращает конфликты наложением блокировок на объекты базы данных (строки или таблицы). Пессимистичное блокирование гарантируют эксклюзивный доступ к данным, но оно может привести к расширению блокировок и сокращению параллелизма по сравнению с подходом оптимистичного блокирования.
Примером пессимистического блокирования является строгая двухфазная блокировка (2PL), которая гарантирует, что параллельно выполняющиеся транзакции запрашивают и снимают блокировки в строгой и согласованной манере, предотвращая конфликты и поддерживая целостность данных. Строгая 2PL состоит из двух различных этапов: фаза нарастания блокировок и фаза снятия блокировок. На этапе нарастания блокировок транзакция запрашивает блокировки на объекты базы данных перед получением к ним доступа или модификации. Эти блокировки могут быть либо разделяемыми (на чтение) либо эксклюзивными (на запись) блокировками в зависимости от типа транзакции . На этапе снятия блокировок транзакция снимает удерживаемые блокировки на объекты базы данных. Это обычно происходит в конце транзакции (фиксации (commit) или отката (rollback)).
Преимуществами этого метода являются простая реализация и гарантированная согласованность и целостность данных. Недостатком же является высокая конкуренция за блокировки, в том числе, ожидание блокировки, эскалация блокировок, что приводит к узким местам в производительности.
Оптимистичная блокировка
Оптимистичный подход в технике управления параллелизмом исходит из того, что конфликты между транзакциями редки, и это позволяет обрабатывать транзакции без наложения блокировок на объекты базы
данных при выполнении всей транзакции. Конфликты проверяются, обнаруживаются и разрешаются только во время фиксации транзакции.
Преимуществами этого метода являются рост конкуренции, сокращение накладных расходов на блокировки, что ведет к линейному росту масштабируемости. К недостаткам относятся высокая степень отказов в результате обнаружения конфликта во время фиксации и проблемы с целостностью данных.
Многоверсионное управление параллелизмом (MVCC)
Этот метод управления параллелизмом используется в системах баз данных для предоставления доступа к разделяемым объектам базы данных при поддержании согласованности и изоляции данных. MVCC обеспечивает каждую транзакцию согласованным снимком данных, которые имели место на момент начала транзакции, даже если другие транзакции параллельно изменяют данные.
MVCC работает очень хорошо в PostgreSQL для операций чтения. Когда приходится обновлять данные, PostgreSQL должен все же применять блокировки (которые являются пессимистичными) на уровне строки, чтобы гарантировать согласованность и предотвращать конфликты между параллельно исполняющимися транзакциями. PostgreSQL обеспечивает блокировки различных типов для управления параллельностью и поддержания согласованности данных в многопользовательской среде. Эти блокировки можно классифицировать по нескольким категориям на основе их области применения и назначения. Ниже приведены наиболее общие типы используемых блокировок (ссылка):
- Блокировки уровня строки/кортежа
- Блокировки уровня страницы
- Совещательные блокировки
Ядро PostgreSQL автоматически выполняет обслуживание блокировок в фоновом режиме для большинства обычных операций, таких как обновление и удаление. Ядро базы данных накладывает и снимает блокировки в зависимости от выполняемых операторов, уровня изоляции транзакций и объема данных. Мы обсудим это подробно в следующей статье - "Погружение в блокировки и тупики PostgreSQL".
Теперь мы знаем об аспектах управления параллелизмом баз данных. Давайте поговорим детально о строительных блоках MVCC применительно к PostgreSQL.
Строительные блоки MVCC в PostgreSQL
Существует 6 ключевых строительных блоков MVCC, которые очень важны для понимания того, как работает в PostgreSQL управление параллелизмом:
- ID транзакции
- Версионность кортежа
- Правила проверки видимости
- Согласованность чтения
- Операции записи
- Сборка мусора
В этом разделе я рассмотрю каждый из этих элементов, чтобы сделать ясными основы.
ID транзакции (XID)
Каждой транзакции присваивается уникальный идентификатор транзакции (ID), который называется Transaction ID (XID). Это 32-битовое (4 байта) значение, которое однозначно идентифицирует транзакцию в кластере баз данных PostgreSQL. Он автоматически генерируется менеджером транзакций, когда транзакция начинается, и сохраняет связь с транзакцией вплоть до фиксации или отката транзакции.
При 2^(32-1) мы можем иметь 2,147,483,648 ID транзакций в кластере. При достижении этого предела значения перестанут расти, и ID транзакций будут повторно использоваться.
Замечание:
ID транзакции 0 (нуль) резервируется, 1 используется в качестве идентификатора начальной транзакции на этапе инициализации кластера, а 2 используется как идентификатор замороженной транзакции.
Встроенная функция pg_current_xact_id() возвращает ID текущей транзакции (XID) в вызывающей сессии. Этот вызов сам создает новую транзакцию, когда вы вызываете ее первый раз в пределах единицы работы. Например:

Менеджер транзакций PostgreSQL выделяет XID, когда вызывается pg_current_xact_id () или выполняется операция UPDATE, DELETE, INSERT. Однако BEGIN транзакции или операция SELECT не будет выделять ID транзакции. Встроенная функция pg_current_xact_id_if_assigned () может использоваться для получения ID текущей транзакции или NULL, если транзакции не присвоен XID.

8-байтовое слово для улучшения ID транзакции (xid8) в PostgreSQL
Начиная с PostgreSQL 13, были внесены изменения в коде, что позволяет иметь 64-битовые (8 байт) ID транзакций, т.е. вплоть до 9,223,372,036,854,775,808 (9223372 миллиардов ID по сравнению с имевшимися 2.2 миллиарда), которые не повторяются в течение срока жизни установки. Следующие структуры данных претерпели изменения в связи с использованием 8-байтовых ID транзакции (xid8):
- Системный каталог PostgreSQL
- Функции и процедуры
- Внутренние рабочие процессы, которые обрабатывают SQL-запросы
- Утилиты PostgreSQL
- Слоты репликации и VACUUM
Однако проблема состоит в том, чтобы преобразовать существующую структуру данных XMIN и XMAX из xid4 в xid8 в работающей базе данных, что затрудняет выполнение преобразования по месту. Более подробно о xid8 смотрите в будущей статье.
Управление версиями кортежей
В PostgreSQL каждый кортеж (строка) в таблице базы данных включает два поля ID транзакции (XID), известных как xmin и xmax. Эти поля представляют минимальное и максимальное ID транзакций, которым разрешалось видеть или получать доступ к определенной строке. Они играют важную роль в механизме многоверсионного управления параллелизмом (MVCC) для поддержания видимости и согласованности данных.
Ниже приводятся характеристики полей xmin и xmax.
xmin (ID создающей транзакции):
- Поле xmin содержит ID транзакции, которая создала эту версию строки.
- Показывает минимальный ID транзакции, которой позволено видеть эту версию строки.
- Любая транзакция, у которой ID ниже xmin, может видеть и иметь доступ к версии строки.
- xmin устанавливается, когда вставляется или создается новая версия строки.
xmax (ID удаляющей транзакции):
- В поле xmax находится ID транзакции (XID), которая удалила или пометила удаленной версию строки.
- Показывает максимальный ID транзакции, которой позволено видеть эту версию строки.
- Только транзакции с ID ниже xmax могут видеть версию строки.
- Если xmax установлено в бесконечность (представляется как 0), это означает, версия строки в настоящее время не удалена или не отмечена как удаленная какой-либо транзакцией.
Давайте возьмем пример и посмотрим, как обеспечивается управление версиями в таблице.

В этом примере xmin для первого кортежа равен 609167. Это XID транзакции, которая вставила этот кортеж. Значение в столбце xmax установлено в 0, означающее, что кортеж активен (срок действия установлен на бесконечность), и не было выполнено ни обновления, ни удаления этого кортежа.
Столбец ctid является системным столбцом, который представляет физическое размещение или адрес строки в таблице. Он состоит из двух частей: номера блока и индекса кортежа. Номер блока идентифицирует блок диска, где хранится строка, а индекс кортежа представляет позицию строки внутри блока.
На рисунке 1 показано управление версиями кортежей в PostgreSQL на простом примере. Сессия session #1 читает кортежи из таблицы account_info, когда xmax установлен на бесконечность (нуль) - это означает отсутствие модификаций кортежей, и что они были активными версиями. Вы можете заметить, что ctid установлен в (0,1) (0,2), означающее, что оба кортежа хранятся последовательно в блоке 0, а в этой таблице находится только 2 кортежа. Когда сессия session #2 обновляет account_type для кортежа с account=1, xmin изменяется с 609167 на 609169, отражая тот факт, что транзакция выполняет обновление. Вы можете также заметить изменение ctid с (0,1) (0,2) на (0,2) (0,3); это означает, что мы имеем 3 кортежа в таблице, находящихся в блоке 0. Почему у нас 3 кортежа в таблице, когда мы видим только 2 кортежа? Это происходит потому, что PostgreSQL сохранил старую версию кортежа по двум причинам: (1) - имеется открытая транзакция, которая читает прежнюю версию кортежа, валидную между txid 609167 и 609169, и (2) - последнее изменение еще не было зафиксировано в сессии session #2.
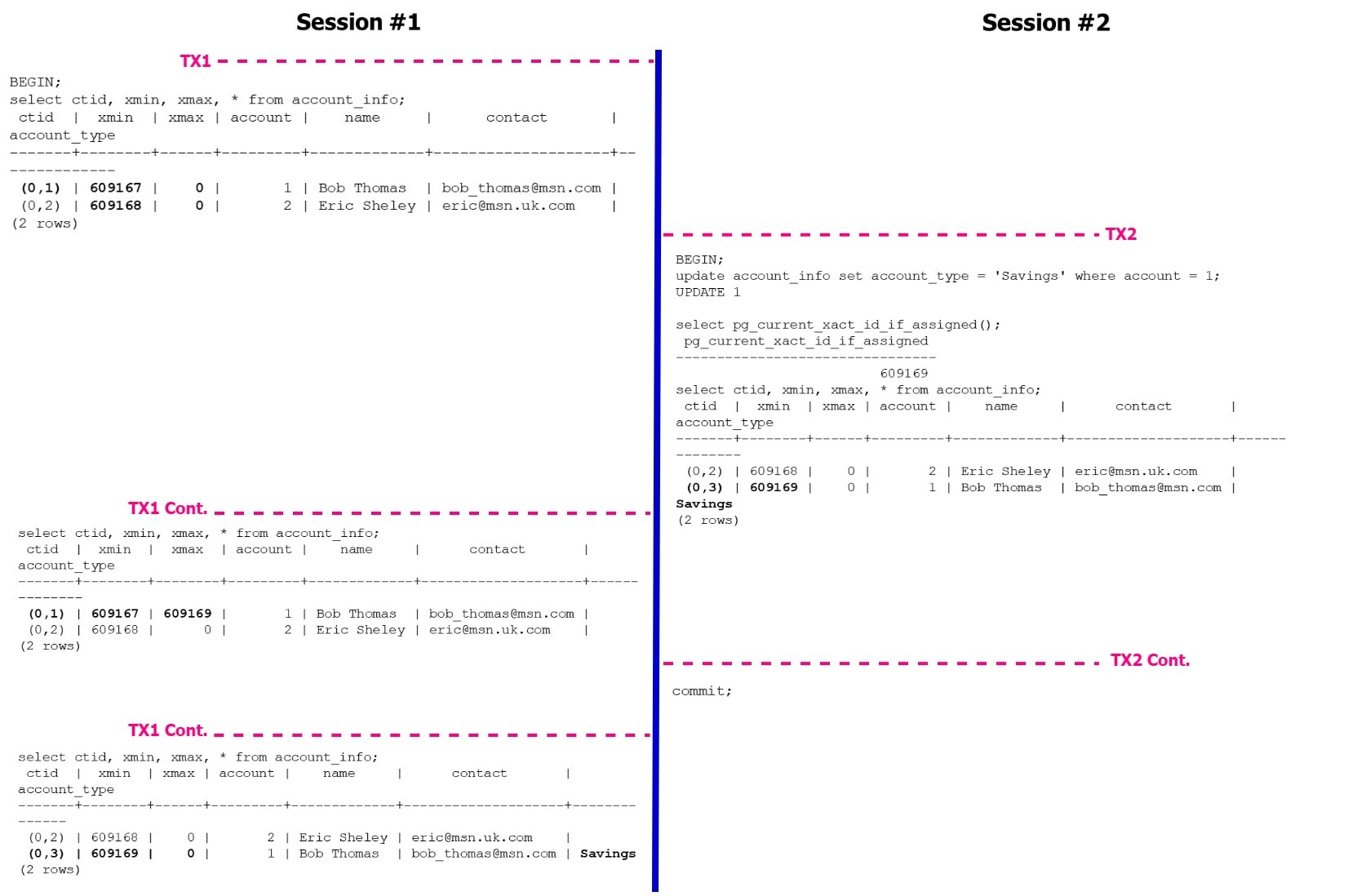
Рисунок 1: Пример управления версиями в PostgreSQL
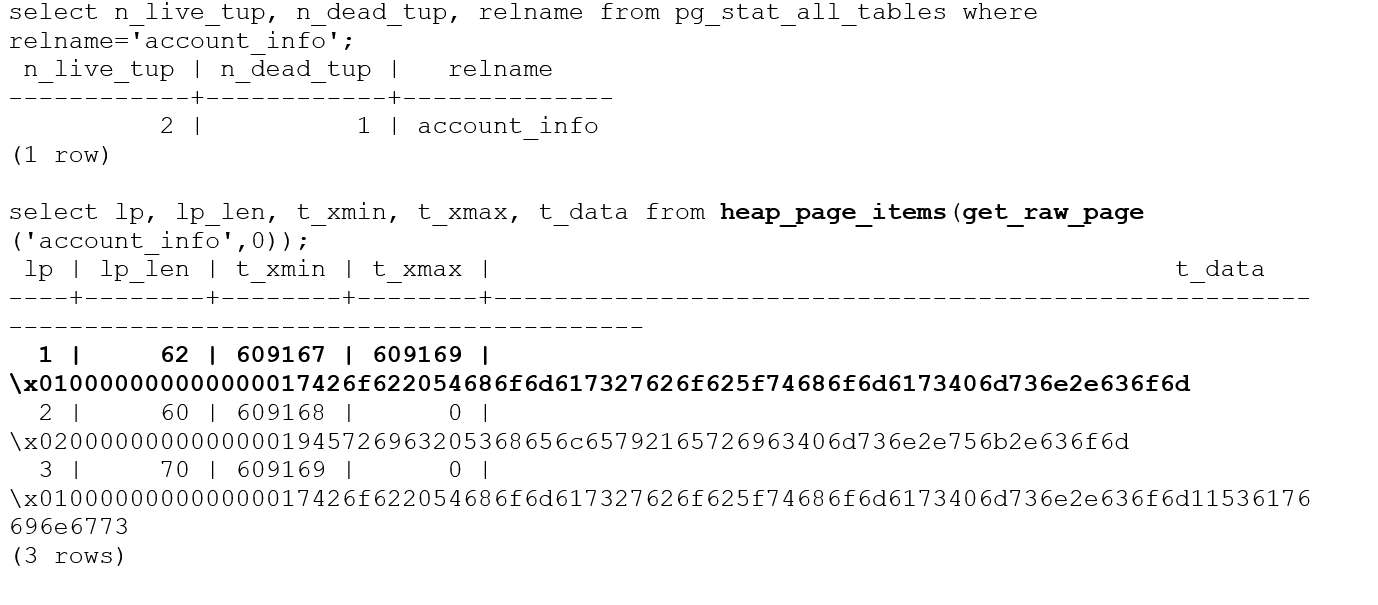
Модуль pageinspect в PostgreSQL обеспечивает набор функций, которые позволяют проверять и анализировать содержимое страниц базы данных на низком уровне. Это модуль особенно полезен для отладки, поиска неполадок и понимания внутренней структуры страниц базы данных PostgreSQL. Например, мы можем проверить таблицу account_info, чтобы вытащить информацию о всех трех кортежах (2 активных кортежа и 1 мертвый).
Правила проверки видимости
В механизме многоверсионного управления параллелизмом (MVCC) в PostgreSQL правила проверки видимости используются для определения того, какие версии данных являются видимыми в транзакционном снимке. Эти правила гарантируют, что каждая транзакция видит согласованный снимок базы данных, полученный на время начала транзакции.
Имеются следующие правила проверки видимости в PostgreSQL:
- Сравнение ID транзакции (XID): Каждая версия данных в PostgreSQL имеет связанный ID транзакции, указывающий на транзакцию, которая создала или модифицировала их. Для определения видимости версии данных в снимке транзакции применяется следующее правило:
xmin <= pg_current_xact_id ()
AND (xmax = 0 OR pg_current_xact_id () < xmax)
- Если xmin версии данных меньше, чем XID транзакции, она считается зафиксированной до момента времени начала транзакции и будет видима в транзакции.
- Если xmin версии данных больше или равно XID транзакции, она считается еще не зафиксированной или модифицированной после времени начала транзакции и не будет видима в транзакции. Однако кортеж будет видим даже при xmin > pg_current_xact_id (), если уровнем изоляции является READ COMMITTED. Например:



В этом примере txid 609176 все еще может видеть зафиксированные данные транзакцией txid 609177, которая имеет более поздний идентификатор транзакции. В PostgreSQL, когда при уровне изоляции READ COMMITTED стартует новый запрос, берется новый снимок состояния базы данных. Этот снимок представляет зафиксированное состояние базы данных на момент времени начала запроса. По этой причине допускается видимость кортежей при xmin > pg_current_xact_id (). - Диапазон ID транзакций снимка: Снимок транзакции включает диапазон ID транзакций, который определяет XID версий данных, видимых в транзакции. Например, вы можете использовать информационную функцию снимка pg_current_snapshot () для отображения диапазона идентификаторов транзакций снимков.
mvcc=# begin;
BEGIN
mvcc=*# update account_info
set account_type = 'Checking'
where account = 2;
UPDATE 1
mvcc=*# select pg_current_snapshot();
pg_current_snapshot
---------------------
609172:609172:
(1 row)
mvcc=*# select pg_last_committed_xact ();
pg_last_committed_xact
--------------------------------------------
(609169,"2023-07-09 01:12:03.883742+00",0)
(1 row)
Снимок включает XID собственной транзакции и может включать диапазон других значений XID на основе выбранного уровня изоляции.
- Read Committed: Снимок транзакции включает только собственный XID, позволяя видеть только версии зафиксированных данных, которые имелись до времени начала транзакции.
- Repeatable Read: Снимок транзакции включает свой собственный XID и все значения XID, которые уже были зафиксированы на время начала, позволяя ей видеть согласованный снимок данных на протяжении всего времени выполнения транзакции.
- Serializable: Снимок транзакции включает диапазон значений XID вплоть до XID транзакции, позволяя ей видеть согласованный снимок и предотвращая конфликты с параллельно выполняющимися транзакциями, модифицирующими те же самые данные.
- Информация о видимости: Каждая версия данных в PostgreSQL имеет связанную с ней информацию видимости, включая минимальный XID (xmin) и максимальный XID (xmax), которым позволено видеть версию. Эти значения используются для определения видимости в зависимости от снимка транзакции.
- Если XID транзакции больше, чем xmin, версия данных видна в транзакции.
- Если XID транзакции больше или равен xmax, версия данных не видна в транзакции.
- Если xmin меньше, чем XID транзакции и xmax больше, чем XID транзакции, могут быть выполнены дополнительные проверки для обработки особых случаев, таких как незавершенные транзакции или блокировки, удерживаемые на уровне кортежа.
Применяя эти правила проверки видимости, PostgreSQL гарантирует, что каждая транзакция видит согласованный снимок данных в зависимости от времени ее начала и уровня изоляции. Это позволяет реализовать параллельный доступ к базе данных при поддержке согласованного чтения и изоляции транзакции.
Согласованность чтения
Согласованность чтения означает гарантию, что транзакция видит согласованный снимок базы данных на момент начала транзакции вне зависимости от изменений, выполняемых параллельно другими транзакциями. Согласованность чтения означает, что доступ к данным остается стабильным и согласованным на все время выполнения транзакции.
Давайте более внимательно рассмотрим такие явления чтения, известные как аномалии и представляющие собой нежелательное поведение, которое может иметь место в конкурирующих транзакциях базы данных, когда несколько транзакций параллельно читают и модифицируют одни и те же данные. Эти явления могут привести к несогласованным или неожиданным результатам, если не приняты надлежащие меры управления изоляцией и параллельностью.
Грязное чтение - Это явление может иметь место при параллельно выполняющихся транзакциях. Это происходит, когда одна транзакция читает данные, которые были модифицированы другой транзакцией, но еще не зафиксированы. Другими словами, транзакция читает незафиксированные или грязные данные. Это полностью предотвращается в PostgreSQL (однако все еще возможно в других реляционных системах баз данных, таких как SQL Server и Db2), и мы не можем читать незафиксированные данные.
Неповторяемое чтение - Это явление имеет место, когда транзакция читает одну и ту же строку или кортеж несколько раз в процессе выполнения, но значения данных изменяются или исчезают (удалены) между чтениями из-за их параллельного изменения другими транзакциями.
Фантомное чтение - Это имеет место, когда транзакция извлекает набор строк на основе некоторого условия, а между последовательными чтениями другая транзакция вставляет данные, удовлетворяющие тому же условию. В результате второе чтение включает дополнительные строки или пропускает ранее полученные строки, что приводит к несогласованному результирующему набору.
Аномалия сериализации - Имеет место, когда вывод выполнения параллельно выполняющихся транзакций не согласуется с выводом выполнения тех же транзакций при их последовательном выполнении при всех возможных упорядочиваниях.
В PostgreSQL доступны различные уровни изоляции транзакций для управления параллельностью и согласованностью транзакций базы данных. Каждый уровень изоляции определяет видимость и поведение блокировок для параллельно выполняющихся транзакций, и PostgreSQL поддерживает следующие уровни изоляции:
1. Read Committed (чтение зафиксированных данных - по умолчанию):
- Обеспечивает согласованное чтение, гарантируя, что транзакция видит только те данные, которые были зафиксированы на момент начала выполнения запроса.
- Препятствует грязному чтению, требуя фиксации данных, прежде чем они станут видимы другим транзакциям.
- Допускает неповторяемое чтение и фантомное чтение, т.к. параллельно выполняющиеся транзакции могут изменять данные между чтениями.
- Обеспечивает хороший баланс между согласованностью и параллельностью, и подходит для многих приложений.
2. Repeatable Read (повторяемое чтение):
- Обеспечивает более высокий уровень согласованности по сравнению с Read Committed.
- Гарантирует, что транзакция видит согласованный снимок базы данных на момент начала выполнения транзакции.
- Препятствует грязному чтению и неповторяемому чтению, применяя блокировки чтения на доступные данные, запрещая модифицировать данные параллельным транзакциям.
- Допускает фантомные чтения, т.к. параллельные транзакции могут вставлять новые строки, которые удовлетворяют критериям запроса.
- Обеспечивает более строгую гарантию согласованности данных, но может привести к росту проблем параллельности из-за наложенных блокировок.
3. Сериализация
- Обеспечивает наивысший уровень изоляции и гарантирует упорядоченность транзакций.
- Гарантирует, что конкурирующие транзакции ведут себя так, как будто они выполнялись последовательно, не вызывая аномалий параллельности.
- Препятствует грязным чтениям, неповторяемым чтениям и фантомным чтениям.
- Может привести к росту блокировок и потенциальным конфликтам сериализации, приводящим к росту уровня блокирования и уменьшению числа параллельно выполняющихся транзакций.
Таблица 1 демонстрирует явления, которые могут иметь место при данном уровне изоляции. Хотя PostgreSQL допускает установку уровня изоляции uncommitted (чтение незафиксированных данных), он ведет себя в точности как read committed (чтение зафиксированных данных).
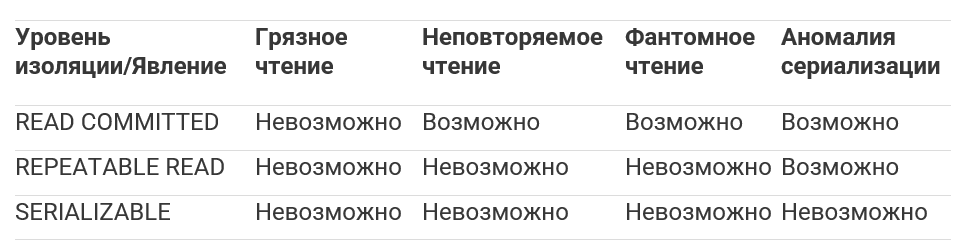
Таблица 1: Уровни изоляции транзакций и явление чтения
Давайте посмотрим на уровень изоляции Read Committed и его поведение. На рисунке 2 показано как должно работать поведение грязного чтения. PostgreSQL всегда читает зафиксированную версию кортежа, и грязное чтение невозможно. Заметим, что вы можете установить уровень изоляции на уровне транзакции или на уровне базы данных.
Замечание. По умолчанию уровнем изоляции, установленным на уровне базы данных, является read committed. Вы можете использовать команду ALTER DATABASE для его изменения, как показано ниже:
ALTER DATABASE ${dbname}
SET DEFAULT_TRANSACTION_ISOLATION TO 'repeatable read'; 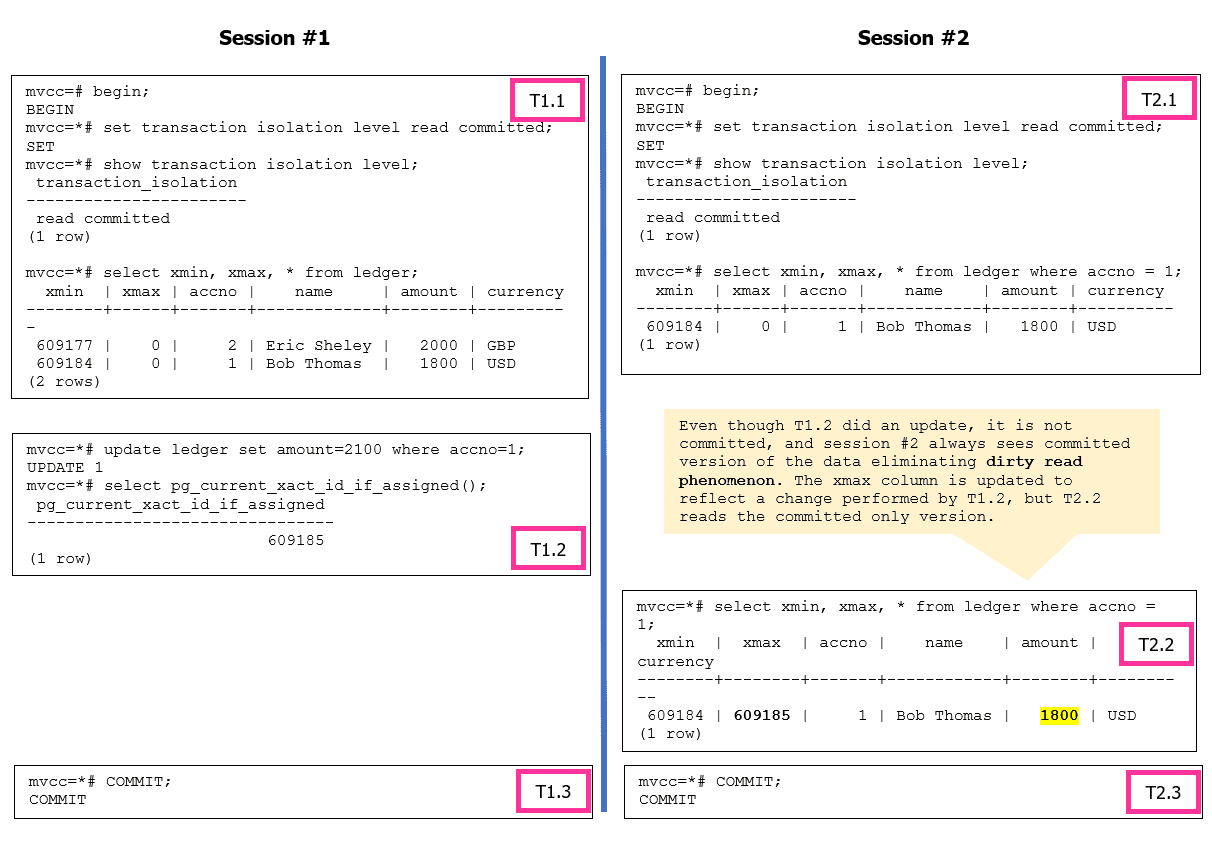
Рисунок 2. Явление грязного чтения невозможно в PostgreSQL
Рисунок 3 иллюстрирует возможность появления неповторяемого чтения и фантомного чтения, когда уровень изоляции установлен в READ COMMITTED.


Рисунок 3. Явление неповторяемого и фантомного чтений возможны в PostgreSQL
Давайте посмотрим на уровень изоляции Repeatable Read и его поведение. Нарисунке 4 показан ваниант, как PostgreSQL разрешает аномалии неповторяемого чтения и фантомного чтения. Аномалия сериализации по-прежнему имеет место в зависимости от того, как спроектировано приложение.


Рисунок 4. Операции при уровне изоляции Repeatable Read
Что произойдет, если предпринята попытка обновления того же кортежа в сессии session #2? Давайте проверим.
mvcc=*# update ledger set amount = 2200 where accno = 1;
ERROR: could not serialize access due to concurrent update
mvcc=!# select pg_current_snapshot ();
ERROR: current transaction is aborted, commands ignored until end of transaction block
mvcc=!# rollback;
ROLLBACKСообщение об ошибке говорит об ошибке сериализации во время параллельной работы транзакций. Она происходит, когда две или более транзакций пытаются изменить одни и теже данные одновременно, что приводит к конфликтам, нарушающим строгую гарантию упорядочивания.
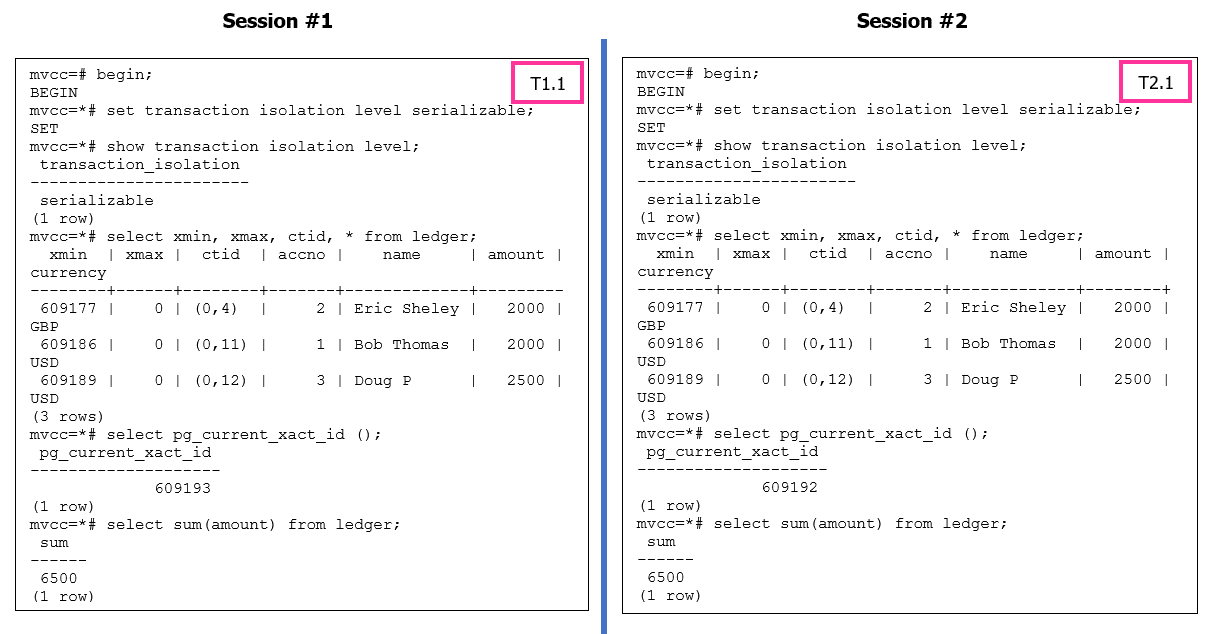
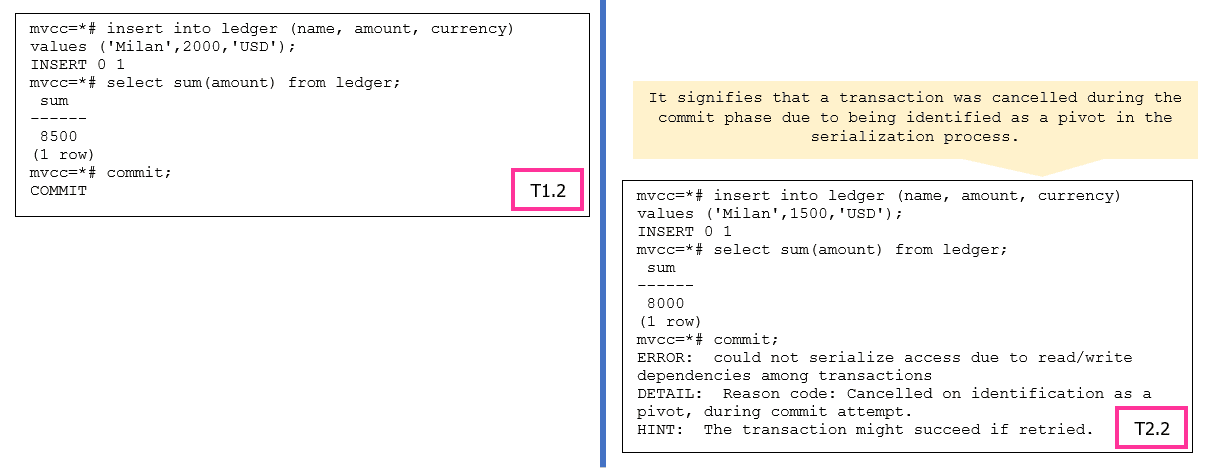
Рисунок 5. Операции на сериализуемом уровне изоляции
При уровне изоляции SERIALIZABLE в PostgreSQL транзакции выполняются так, как будто они запускаются по очереди, что гарантирует согласованность данных. Для поддерки этой строгой упорядоченности PostgreSQL может идентифицировать транзакцию как "опорная" (pivot) при возникновении конфликта с другими параллельно выполняющимися транзакциями.
"Основная" транзакция - это транзакция, которая служит опорной точкой в процессе упорядочения. При возникновении конфликта PostgreSQL может выбрать одну транзакцию в качестве основной и прервать другие конфликтующие транзакции для сохранения согласованности. Сообщение об ошибке указывает, что отменяемая транзакция была идентифицирована как опорная во время попытки фиксации.
Более подробно об этом смотрите здесь.
Операции записи
В базах данных PostgreSQL оператор INSERT прост и не отличается от аналогичных операторов в других базах данных. Операцию записи из разделяемых буферов в файл журнала транзакций и на страницы данных обрабатывают процессы фоновой записи и записи WAL.
Более интересны операторы UPDATE и DELETE. Давайте рассмотрим операцию UPDATE. Когда операция UPDATE в PostgreSQL модифицирует строку, она следует механизму многоверсионного управления параллелизмом (MVCC). PostgreSQL выполнит внутри удаление и вставку вместо модификации существующей строки по месту. Это делается для обеспечения согласованности данных и эффективной обработки управления параллелизмом посредством записи, которая не блокирует чтение, и чтением, которое не блокирует запись.
Каждая операция UPDATE выполняет псевдо удаление, т.е. исходная строка помечается для удаления, создавая новую версию строки с флажком удаления, и вставку - вставляется новая строка с обновленными значениями, создавая новую версию строки.
Для простоты давайте возьмем пример UPDATE с уровнем изоляции READ COMMITTED (по умолчанию). В примере ниже каждая сессия может начать выполнение первой, или обе сессии могут выполняться параллельно.
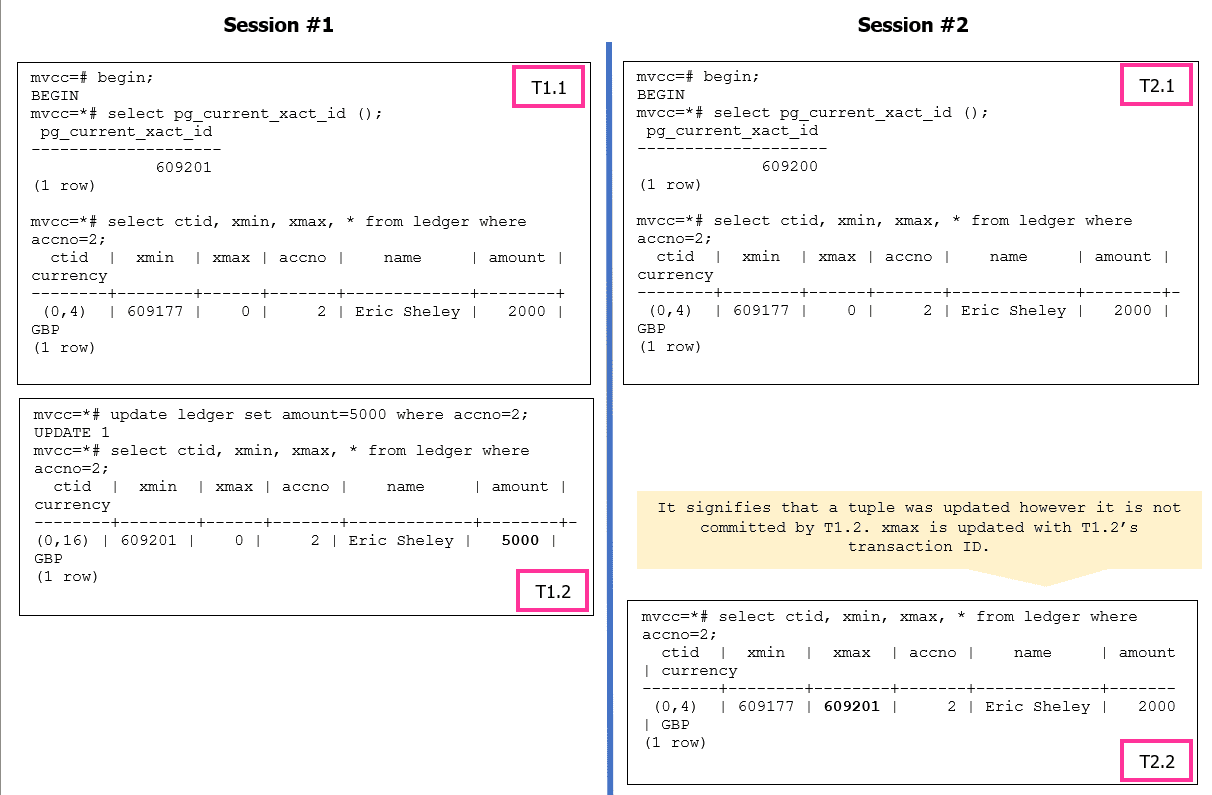

Функции модуля pageinspect могут использоваться для анализа данных на уровне страницы, как для таблицы, так и для индексов. В случае операции DELETE xmax будет обновлено на значение идентификатора транзакции, которая выполняет DELETE и помечает кортеж мертвым.
Сбор мусора
В PostgreSQL уборкой мусора называется процесс освобождения пространства диска, занятого удаленными или устаревшими данными. Когда данные удаляются или обновляются в PostgreSQL, они не сразу удаляются с диска, а помечаются пригодными для сборки мусора, и фактически дисковое пространство освобождается позже в процессе autovacuum.
В нашем примере мы имеем 4 живых кортежа и 12 мертвых кортежей, эти мертвые кортежи могут быть вычищены с помощью VACUUM. Команда VACUUM используется для выполнения вакуумации таблицы (реогранизации данных). Она освобождает пространство диска, физически перестраивая таблицу и связанные с ней индексы, и может более интенсивно использовать ресурсы по сравнению с регулярными операциями VACUUM.
mvcc=# VACUUM VERBOSE ledger;
INFO: vacuuming "mvcc.public.ledger"
INFO: finished vacuuming "mvcc.public.ledger": index scans: 1
pages: 0 removed, 1 remain, 1 scanned (100.00% of total)
tuples: 12 removed, 4 remain, 0 are dead but not yet removable
removable cutoff: 609251, which was 0 XIDs old when operation ended
index scan needed: 1 pages from table (100.00% of total) had 12 dead item identifiers removed
index "ledger_pkey": pages: 2 in total, 0 newly deleted, 0 currently deleted, 0 reusable
avg read rate: 0.000 MB/s, avg write rate: 0.000 MB/s
buffer usage: 11 hits, 0 misses, 0 dirtied
WAL usage: 4 records, 1 full page images, 8480 bytes
system usage: CPU: user: 0.00 s, system: 0.00 s, elapsed: 0.00 s
VACUUMОднако число мертвых кортежей по-прежнему 12, как показано в каталоге. Это просто информация в системном каталоге, и мы должны будем выполнить команду ANALYZE, чтобы обновить статистику таблицы, включая информацию о распределении данных, гистограмм столбцов и связи между столбцами. Эта статистика используется оптимизатором запросов для генерации эффективных планов выполнения.

Заключение
MVCC (многоверсионное управление параллелизмом) является механизмом управления параллелизмом, который используется в PostgreSQL для обработки параллельного доступа к данным. Он позволяет множеству транзакций параллельно читать и записывать данные при поддерживаемом уровне изоляции транзакций и обеспечении согласованности. В этой статье мы рассмотрели специфику MVCC и строительные блоки MVCC в деталях. В последующих статьях мы глубже изучим каждый раздел, а именно внутреннее устройство VACUUM, хранилища, индекса B-Tree и блокирования.
Ссылки по теме
1. Введение в управление параллелизмом в PostgreSQL
2. Уровни изоляции транзакций
3. PostgreSQL (auto) vacuum - уже не тайна
4. Нормализация для сокращения блокировок
Обратные ссылки
Автор не разрешил комментировать эту запись
Комментарии
Показывать комментарии Как список | Древовидной структурой