
Отключение некластеризованных индексов для развлечения и пользы
Пересказ статьи Andy Galbraith. Disabling Non-Clustered Indexes For Fun and Profit
Одним из часто цитируемых практических советов в ETL является отключение некластеризованных индексов при загрузке данных. Общепринятое мнение заключается в том, что вы отключаете некластеризованные индексы, выполняете загрузку, а затем включаете некластеризованные индексы, что функционально перестраивает их с вновь загруженными данными (шаг, который должен выполняться после загрузки любого объема, даже если вы НЕ отключали ваши индексы - перестраивайте эти ставшие фрагментированными индексы!)
Так почему же кажется, что никто этого не делает?
ВАЖНОЕ ЗАМЕЧАНИЕ - не отключайте кластеризованный индекс, когда вы загружаете данные или всякий раз, когда вы хотите, чтобы таблица оставалась доступной. Отключение кластеризованного индекса делает объект (таблицу или представление) недоступными.
Если вы отключаете кластеризованный индекс, то отключаете функционирование объекта, и любые попытки получить доступ к этому объекту вызовут ошибку 8655:
Недавно я столкнулся с ситуацией клиента, у которого процесс загрузки выполнялся уже свыше 24 часов - не один запрос суточной продолжительности, а скорее последовательность процессов, выполнение которых обычно занимает более 24 часов. Ситуация ухудшилась так, что пострадали и другие вещи, потому что процесс занимает так много времени. И они попросили меня проверить это.
Я начал с основ, и сразу выскочила ожидаемая продолжительность жизни страницы (PLE - Page Life Expectancy) в соответствующий период:
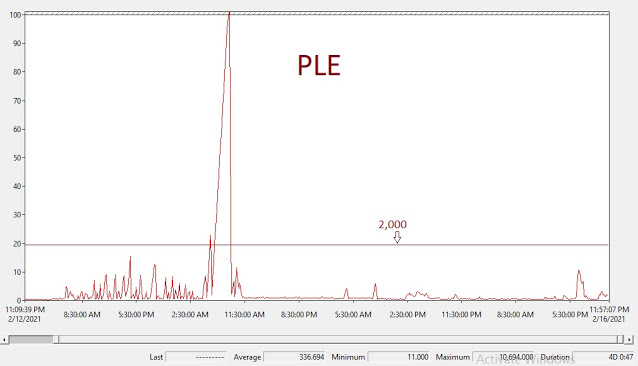
Сервер имеет 128Гб RAM... поэтому PLE ниже 1000 считается довольно низкой.
Я использовал расширенные события (XEvents) для сбора запросов с большим выделением памяти, и они выявили проблему, которую клиент ранее рассматривал, но не обработал - отключение индексов во время загрузки.
Вот код, который я использовал для сессии XEvents, чтобы вытащить запросы с большим выделением памяти - он собирает любые запросы с выделением памяти свыше 8Мб (число, которое вы можете поменять в предложении WHERE), и вызывающий запрос:
Затем запрос на получение данных - он динамически получает путь к журналу ошибок по умолчанию, а затем запрашивает выходной файл XEL из целевого файла event_file в сеансе по этому пути:
Оказалось, что запросы, которые потребляли максимальную память в течение этого периода времени, были довольно обычными:
Проблема для меня состояла в том, что выделение памяти (memory grant) обычно исходит от операций SORT и HASH (посмотрите отличное описание от Erik Darling), и этот запрос очевидно не делает ни того, ни другого - это простой запрос вставки из одной таблицы в другую, но план запроса выглядит примерно так:
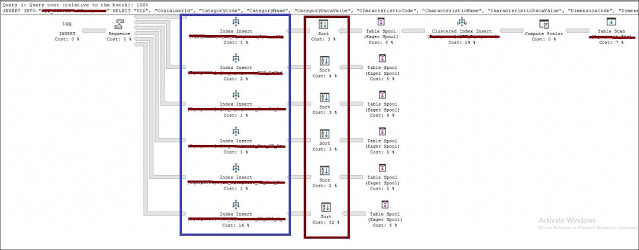
Довольно странно, правда? Со всеми этими сортировками не удивительно, что SQL Server хочет получить для этого запроса гигантское количество памяти!
Но откуда эти шесть различных операций SORT на одном обычном INSERT...SELECT? Затем я понял почему:
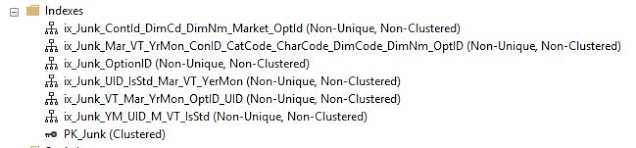
Шесть сортировок...для ШЕСТИ некластеризованных индексов!
Вставка строк в таблицу с включенными некластеризованными индексами требуют SORT для добавления строк в такой индекс - INSERT не может просто скинуть строки в конец индекса, а должен отсортировать входные строки в соответствии с сортировкой индексов.
В качестве теста я создал копию целевой таблицы, на которой я мог бы настроить индексы, и вторую копию вообще без индексов; и мой план запроса INSERT...SELECT для копии БЕЗ индексов выглядел немного лучше:

Так как я выполнял тестирование, я скопировал два INSERT...SELECT в одно окно запроса, и получил планы для каждого, чтобы я мог их сравнить:
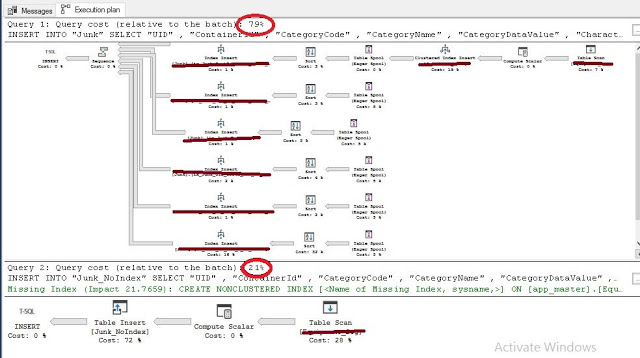
Стоимость запросов в Management Studio всегда следует воспринимать с недоверием, но для сравнения рассмотрим - стоимость шестиступенчатой вставки в четыре раза выше по сравнению с запросом без индексов! Далее в тесте я отключил три индекса на моей копии таблицы, и снова выполнил запрос:
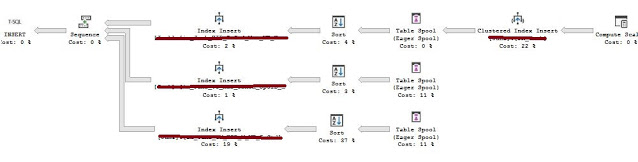
Бинго - шесть потоков теперь упали до трех оставшихся включенных индексов. Я отключил остальные некластеризованные индексы и:

Для последнего сравнения я выполнил двойной запрос на моей копии "со всеми отключенными индексами" и копии "без индексов":

В точку!
Как я упомянул выше, затраты на это состоят в том, что в конце процесса вы должны потратить время на включение индексов снова, что приводит к их перестройке.
Как всегда, ваш случай может отличаться, т.к. непосредственное влияние будет зависеть от размеров таблицы, числа некластеризованных индексов и от много другого - но проверьте, особенно, если ваш процесс выполняется медленнее, чем вы хотите - в этом может заключаться проблема!
ВАЖНОЕ ЗАМЕЧАНИЕ - не отключайте кластеризованный индекс, когда вы загружаете данные или всякий раз, когда вы хотите, чтобы таблица оставалась доступной. Отключение кластеризованного индекса делает объект (таблицу или представление) недоступными.
Если вы отключаете кластеризованный индекс, то отключаете функционирование объекта, и любые попытки получить доступ к этому объекту вызовут ошибку 8655:
Msg 8655, Level 16, State 1, Line 23
Процессор запросов не может произвести план, поскольку индекс 'PK_Person_BusinessEntityID' на таблице или представлении ‘Person’ отключен.
Недавно я столкнулся с ситуацией клиента, у которого процесс загрузки выполнялся уже свыше 24 часов - не один запрос суточной продолжительности, а скорее последовательность процессов, выполнение которых обычно занимает более 24 часов. Ситуация ухудшилась так, что пострадали и другие вещи, потому что процесс занимает так много времени. И они попросили меня проверить это.
Я начал с основ, и сразу выскочила ожидаемая продолжительность жизни страницы (PLE - Page Life Expectancy) в соответствующий период:
Сервер имеет 128Гб RAM... поэтому PLE ниже 1000 считается довольно низкой.
Я использовал расширенные события (XEvents) для сбора запросов с большим выделением памяти, и они выявили проблему, которую клиент ранее рассматривал, но не обработал - отключение индексов во время загрузки.
Вот код, который я использовал для сессии XEvents, чтобы вытащить запросы с большим выделением памяти - он собирает любые запросы с выделением памяти свыше 8Мб (число, которое вы можете поменять в предложении WHERE), и вызывающий запрос:
CREATE EVENT SESSION [Ntirety_MemoryGrantUsage] ON SERVER
ADD EVENT sqlserver.query_memory_grant_usage
(
ACTION(sqlserver.client_app_name,sqlserver.client_hostname,sqlserver.database_id
,sqlserver.database_name,sqlserver.server_principal_name,sqlserver.session_id,sqlserver.sql_text)
WHERE ([package0].[greater_than_uint64]([granted_memory_kb],(8192))))
ADD TARGET package0.event_file(SET filename=N'Ntirety_MemoryGrantUsage',max_file_size=(256)),
ADD TARGET package0.ring_buffer(SET max_events_limit=(0),max_memory=(1048576))
WITH (MAX_MEMORY=4096 KB,EVENT_RETENTION_MODE=ALLOW_SINGLE_EVENT_LOSS,MAX_DISPATCH_LATENCY=5 SECONDS,MAX_EVENT_SIZE=0 KB,MEMORY_PARTITION_MODE=NONE,TRACK_CAUSALITY=OFF,STARTUP_STATE=ON
)Затем запрос на получение данных - он динамически получает путь к журналу ошибок по умолчанию, а затем запрашивает выходной файл XEL из целевого файла event_file в сеансе по этому пути:
USE master
GO
DECLARE @ErrorLogPath nvarchar(400), @XELPath nvarchar(500)
SET @ErrorLogPath = (
SELECT LEFT(cast(SERVERPROPERTY('ErrorLogFileName') as nvarchar(400)),LEN(cast(SERVERPROPERTY('ErrorLogFileName') as nvarchar(400)))-8)
)
SET @XELPath = @ErrorLogPath+'Ntirety_MemoryGrantUsage*.xel'
SELECT DISTINCT *
FROM
(
SELECT
DATEADD(hh, DATEDIFF(hh, GETUTCDATE(), CURRENT_TIMESTAMP), event_data.value(N'(event/@timestamp)[1]', N'datetime'))as Event_time
, CAST(n.value('(data[@name="granted_memory_kb"]/value)[1]', 'bigint')/1024.0 as DECIMAL(30,2)) AS granted_memory_mb
, CAST(n.value('(data[@name="used_memory_kb"]/value)[1]', 'bigint')/1024.0 as DECIMAL(30,2)) AS used_memory_mb
, n.value('(data[@name="usage_percent"]/value)[1]', 'int') AS usage_percent
, n.value ('(action[@name="database_name"]/value)[1]', 'nvarchar(50)') AS database_name
, n.value ('(action[@name="client_app_name"]/value)[1]','nvarchar(50)') AS client_app_name
, n.value ('(action[@name="client_hostname"]/value)[1]','nvarchar(50)') AS client_hostname
, n.value ('(action[@name="server_principal_name"]/value)[1]','nvarchar(500)') AS [server_principal_name]
, n.value('(@name)[1]', 'varchar(50)') AS event_type
, n.value ('(action[@name="sql_text"]/value)[1]', 'nvarchar(4000)') AS sql_text
FROM
(
SELECT CAST(event_data AS XML) AS event_data
FROM sys.fn_xe_file_target_read_file(
@XELPath
, NULL
, NULL
, NULL)
)
AS Event_Data_Table
CROSS APPLY event_data.nodes('event') AS q(n)
) MemoryGrantUsage
ORDER BY event_time descОказалось, что запросы, которые потребляли максимальную память в течение этого периода времени, были довольно обычными:
INSERT INTO "dbo"."Junk"
SELECT "UID"
, "ContainerId"
, "CategoryCode"
, "CategoryName"
, "CategoryDataValue"
, "CharacteristicCode"
, "CharacteristicName"
, "CharacteristicDataValue"
, "DimensionCode"
, "DimensionName"
, "DimensionDataValue"
, "OptionId"
, "NumberOfItems"
, "IsStandard"
, "LanguageId"
, "Market"
, "VehicleType"
, "YearMonth"
, "BatchRefreshDate"
, "CreatedBy"
, "CreatedTimestamp"
, "ModifiedBy"
, "ModifiedTimestamp"
, "BatchId"
FROM "dbo"."Junk_Stg"
where "Market" = 'XYZ'Проблема для меня состояла в том, что выделение памяти (memory grant) обычно исходит от операций SORT и HASH (посмотрите отличное описание от Erik Darling), и этот запрос очевидно не делает ни того, ни другого - это простой запрос вставки из одной таблицы в другую, но план запроса выглядит примерно так:
Довольно странно, правда? Со всеми этими сортировками не удивительно, что SQL Server хочет получить для этого запроса гигантское количество памяти!
Но откуда эти шесть различных операций SORT на одном обычном INSERT...SELECT? Затем я понял почему:
Шесть сортировок...для ШЕСТИ некластеризованных индексов!
Вставка строк в таблицу с включенными некластеризованными индексами требуют SORT для добавления строк в такой индекс - INSERT не может просто скинуть строки в конец индекса, а должен отсортировать входные строки в соответствии с сортировкой индексов.
В качестве теста я создал копию целевой таблицы, на которой я мог бы настроить индексы, и вторую копию вообще без индексов; и мой план запроса INSERT...SELECT для копии БЕЗ индексов выглядел немного лучше:
Так как я выполнял тестирование, я скопировал два INSERT...SELECT в одно окно запроса, и получил планы для каждого, чтобы я мог их сравнить:
Стоимость запросов в Management Studio всегда следует воспринимать с недоверием, но для сравнения рассмотрим - стоимость шестиступенчатой вставки в четыре раза выше по сравнению с запросом без индексов! Далее в тесте я отключил три индекса на моей копии таблицы, и снова выполнил запрос:
Бинго - шесть потоков теперь упали до трех оставшихся включенных индексов. Я отключил остальные некластеризованные индексы и:
Для последнего сравнения я выполнил двойной запрос на моей копии "со всеми отключенными индексами" и копии "без индексов":
В точку!
Как я упомянул выше, затраты на это состоят в том, что в конце процесса вы должны потратить время на включение индексов снова, что приводит к их перестройке.
Как всегда, ваш случай может отличаться, т.к. непосредственное влияние будет зависеть от размеров таблицы, числа некластеризованных индексов и от много другого - но проверьте, особенно, если ваш процесс выполняется медленнее, чем вы хотите - в этом может заключаться проблема!
Обратные ссылки
Автор не разрешил комментировать эту запись
Комментарии
Показывать комментарии Как список | Древовидной структурой