
Как работает секционирование в PostgreSQL и почему вас это должно беспокоить?
Пересказ статьи Adam Furmanek. How Does Partitioning Work in PostgreSQL and Why Should You Care?
Секционирование позволяет разделить логически одну большую таблицу на физические таблицы меньших размеров. Это может улучшить производительность запросов, обеспечивая доступ к меньшему числу строк, оптимизируя чтения со случайным доступом и используя очень таргетированные индексы. Давайте посмотрим, как это работает в PostgreSQL и как Metis их обрабатывает.
Шаблоны
Секционирование - это способ разбиения большой таблицы на меньшие более управляемые части, которые называются секциями. Каждая секция содержит подмножество данных таблицы, определяемое заданным ключом секционирования. Это изменение видно только со стороны ядра. Конечный пользователь не замечает никаких изменений, для него по-прежнему имеется одна таблица, к которой пользователь может иметь доступ вне зависимости от секционирования.
Ключом секционирования может быть диапазон значений (секционирование по диапазону), список заданных значений (секционирование по списку) или математическое выражение (хэш-секционирование). Типичными примерами являются секционирование по дате или по стране. Мы можем построить также пользовательское секционирование с помощью представлений, как будет показано ниже.
Секционирование помогает улучшить производительность запросов посредством исключения нерелевантных данных при обработке запроса. Когда в запросе указано условие, которое соответствует ключу секционирования, PostgreSQL может непосредственно обратиться только к релевантной секции, а не сканировать всю таблицу. Это может существенно ускорить запросы к большим таблицам.
Кроме того, секции могут размещаться на нескольких устройствах хранения или табличных пространствах, делая возможным параллельную обработку и эффективное использование дисков. Они могут также облегчить такие задачи обслуживания данных, как архивация или удаление старых данных, простым удалением или отключением секций.
PostgreSQL обеспечивает различные типы методов секционирования, включая секционирование по диапазону, секционирование по списку и хэш-секционирование. Каждый метод имеет свои преимущества и подходит для различных вариантов использования.
PostgreSQL предоставляет встроенную поддержку для следующих форм секционирования:
- Секционирование по диапазону: Таблица разбивается на "диапазоны", определяемые ключевым столбцом или множеством столбцов без перекрытия диапазонов значений, принадлежащих различным секциям. Например, может быть выполнено разбиение по диапазонам дат или по диапазонам идентификаторов для конкретных объектов бизнеса. Считается, что каждый диапазон включает нижнюю границу и не включает верхнюю. Например, если одна секция включает диапазон от 1 до 10, а следующий - от 10 до 20, то значение 10 принадлежит второй секции, а не первой.
- Секционирование по списку: Таблица разбивается по явному перечислению значений ключа, которые должны принадлежать каждой секции.
- Хэш-секционирование: Таблица разбивается путем указания модуля и остатка для каждой секции. Каждая секция будет содержать те строки, для которых хэш-значение ключа секционирования, деленного на заданный модуль, будет давать заданный остаток.
Мы можем также построить секции с помощью представлений. Мы создаем вручную отдельные таблицы, а затем создаем представление, которое соединяет данные всех этих таблиц.
Давайте рассмотрим практические примеры.
Секционирование по дате
Давайте начнем с создания секционируемой таблицы:
CREATE TABLE orders (
order_id SERIAL,
order_date DATE NOT NULL,
customer_name VARCHAR(255),
product_name VARCHAR(255),
quantity INT
) PARTITION BY RANGE(EXTRACT(YEAR FROM order_date));Важной является последняя строка:
PARTITION BY RANGE(EXTRACT(YEAR FROM order_date))Мы создаем таблицу, которая разбивает данные по году из даты заказа. После этого нам необходимо явно создать таблицы для конкретных значений:
CREATE TABLE orders_2019 PARTITION OF orders FOR VALUES FROM (2019) TO (2020);
CREATE TABLE orders_2020 PARTITION OF orders FOR VALUES FROM (2020) TO (2021);
CREATE TABLE orders_2021 PARTITION OF orders FOR VALUES FROM (2021) TO (2022);Мы создали три секции для трех разных годов. Видно, что мы включили год в имена таблиц. Это типичный подход, который улучшает обслуживание.
Давайте теперь добавим некоторые данные:
INSERT INTO orders (order_date, customer_name, product_name, quantity)
VALUES ('2019-01-01', 'John Smith', 'Product A', 10),
('2019-02-15', 'Jane Doe', 'Product B', 5),
('2019-04-20', 'Bob Johnson', 'Product C', 2),
('2019-07-10', 'Alice Brown', 'Product A', 7),
('2019-12-30', 'Mike Wilson', 'Product B', 8);
INSERT INTO orders (order_date, customer_name, product_name, quantity)
VALUES ('2020-02-14', 'John Smith', 'Product A', 15),
('2020-03-20', 'Jane Doe', 'Product B', 3),
('2020-06-05', 'Bob Johnson', 'Product C', 10),
('2020-08-15', 'Alice Brown', 'Product A', 5),
('2020-11-25', 'Mike Wilson', 'Product B', 2);
INSERT INTO orders (order_date, customer_name, product_name, quantity)
VALUES ('2021-01-07', 'John Smith', 'Product A', 4),
('2021-03-15', 'Jane Doe', 'Product B', 12),
('2021-05-20', 'Bob Johnson', 'Product C', 6),
('2021-09-01', 'Alice Brown', 'Product A', 3);Теперь мы можем узнать количество заказов:
SELECT COUNT(*) FROM orders;Результат:

Metis показывает, что читались следующие таблицы:

мы видим, что был выполнен доступ к всем трем секциям.
Также можно взять заказы из конкретной таблицы, например:
SELECT COUNT(*) FROM orders_2019;Результаты:

Metis показывает следующий анализ:

Мы видим, что была прочитана только одна таблица. Однако если мы выполним следующий запрос:
SELECT COUNT(*) FROM orders
WHERE order_date BETWEEN '2020-01-01' AND '2020-12-31';с таким результатом:

то получим следующее выполнение:

Причиной является то, что движок не считает наши фильтры фильтрами секционирования. Нам нужно изменить запрос следующим образом:
SELECT COUNT(*) FROM orders
WHERE order_date BETWEEN '2020-01-01' AND '2020-12-31'
AND EXTRACT(YEAR FROM order_date) = 2020Metis показывает:

Как видно, секции могут улучшить производительность запросов, но следует быть внимательными при их использовании. Metis может помочь нам в этом случае легко устранять неполадки и оптимизировать запросы к базе данных.
Вы можете также проверять секции. Этот запрос показывает общее число секций и строк:
SELECT
pg_inherits.inhparent::regclass AS table_name,
pg_class.relkind,
COUNT(pg_inherits.inhrelid::regclass) AS count_partitions,
SUM(pg_class.relpages) as total_pages,
SUM(pg_class.reltuples) as total_rows
FROM pg_inherits
JOIN pg_class ON pg_inherits.inhrelid = pg_class.oid
WHERE pg_class.relkind = 'r'
GROUP BY pg_inherits.inhparent::regclass, pg_class.relkindВывод:

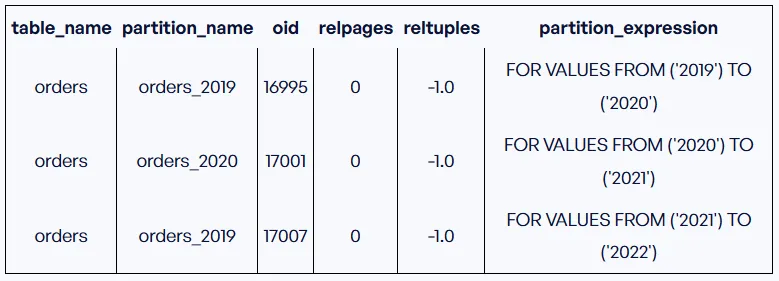
Этот запрос показывает для каждой секции выражение секционирования:
SELECT
pg_inherits.inhparent::regclass AS table_name,
pg_inherits.inhrelid::regclass AS partition_name,
pg_class.oid,
pg_class.relpages,
pg_class.reltuples,
pg_get_expr(pg_class.relpartbound, pg_class.oid, true) as partition_expression
FROM pg_inherits
JOIN pg_class ON pg_inherits.inhrelid = pg_class.oid
WHERE pg_class.relkind = 'r'
ORDER BY pg_inherits.inhparent, pg_inherits.inhrelidВывод:
Секционирование с применением представлений
Теперь давайте реализуем предыдущий пример с помощью представлений. Создадим следующие таблицы:
CREATE TABLE orders_2019 (
order_id SERIAL,
order_date DATE NOT NULL,
customer_name VARCHAR(255),
product_name VARCHAR(255),
quantity INT
);
CREATE TABLE orders_2020 (
order_id SERIAL,
order_date DATE NOT NULL,
customer_name VARCHAR(255),
product_name VARCHAR(255),
quantity INT
);
CREATE TABLE orders_2021 (
order_id SERIAL,
order_date DATE NOT NULL,
customer_name VARCHAR(255),
product_name VARCHAR(255),
quantity INT
);Давайте теперь создадим представление, которое будет включать данные из всех этих таблиц:
CREATE VIEW orders AS (
SELECT * FROM orders_2019
UNION ALL
SELECT * FROM orders_2020
UNION ALL
SELECT * FROM orders_2021
);Давайте, как и прежде, вставим данные:
INSERT INTO orders (order_date, customer_name, product_name, quantity)
VALUES ('2019-01-01', 'John Smith', 'Product A', 10),
('2019-02-15', 'Jane Doe', 'Product B', 5),
('2019-04-20', 'Bob Johnson', 'Product C', 2),
('2019-07-10', 'Alice Brown', 'Product A', 7),
('2019-12-30', 'Mike Wilson', 'Product B', 8);
INSERT INTO orders (order_date, customer_name, product_name, quantity)
VALUES ('2020-02-14', 'John Smith', 'Product A', 15),
('2020-03-20', 'Jane Doe', 'Product B', 3),
('2020-06-05', 'Bob Johnson', 'Product C', 10),
('2020-08-15', 'Alice Brown', 'Product A', 5),
('2020-11-25', 'Mike Wilson', 'Product B', 2);
INSERT INTO orders (order_date, customer_name, product_name, quantity)
VALUES ('2021-01-07', 'John Smith', 'Product A', 4),
('2021-03-15', 'Jane Doe', 'Product B', 12),
('2021-05-20', 'Bob Johnson', 'Product C', 6),
('2021-09-01', 'Alice Brown', 'Product A', 3);Обратите внимание, что мы не вставляем данные в представление. Мы должны вручную указать таблицы для этих данных.
Теперь выполним запрос к таблице:
SELECT COUNT(*) FROM orders Получаем ожидаемый результат:

Анализ от Metis:

Теперь давайте выполним запрос к подмножеству данных:
SELECT COUNT(*) FROM orders
WHERE order_date BETWEEN '2020-01-01' AND '2020-12-31'Результат:

Metis показывает:

Мы видим, что были использованы все таблицы. Однако мы не можем сконфигурировать индекс на этом представлении, чтобы ускорить выполнение, поскольку представления не поддерживают такую операцию:
CREATE INDEX orders_order_date_idx ON orders(order_date)Результат:
[Code: 0, SQL State: 42809] ERROR: cannot create index on relation "orders"
Detail: This operation is not supported for views.Следовательно, мы должны использовать по возможности встроенное секционирование.
Заключение
Секционирование может улучшить производительность запросов и должно входить в наш арсенал средств оптимизации базы данных. Metis может помочь устранить проблемы, связанные с производительностью, и выявить медленные запросы. Есть множество вариантов конфигурации для секционирования, и мы можем всегда построить представления, которые имитируют поведение секционирования.
Ссылки по теме
1. Как решить, нужно ли вам секционировать таблицы
2. Как секционировать таблицы MySQL
3. Основы представлений в PostgreSQL
Обратные ссылки
Автор не разрешил комментировать эту запись
Комментарии
Показывать комментарии Как список | Древовидной структурой