
Как использовать функциональность массивов в SQL Server?
Пересказ статьи Josip Saban. How to Use Array Functionality in SQL Server?
Обработка массива значений внутри процедуры или функции является обычным требованием в большинстве бизнес-кейсов. Поскольку SQL Server не поддерживает переменные типа массива, разработчики используют список значений (главным образом, CSV) на входе.
Табличнозначные параметры (TVP) вместо массивов
SQL Server 2008 ввел функциональность, называемую табличнозначными параметрами (TVP). Она позволяет пользователям объединять значения в таблицу и обрабатывать их в табличном формате. Хранимые процедуры или функции могут использовать такую переменную в операторах соединения. Это дает возможность улучшить производительность и избежать поэлементных операций типа курсора.
Хотя подход на базе таблиц был доступен в течение долгого времени, списки значений в качестве параметров широко использовались по двум следующим причинам:
Чтобы решить эту проблему, специалисты применяют несколько подходов. Некоторые из них включают написание функции CLR .NET или использование XML. Однако, т.к. выполнение функций CLR .NET может быть недоступным во всех средах, а XML обычно является не самым быстрым решением, я остановлюсь на других двух общих подходах. Это методы на основе таблицы чисел и общих табличных выражений (CTE).
Подход на основе таблицы чисел означает, что вы должны вручную создать таблицу, содержащую достаточно строк, чтобы самая длинная строка, которую вы разбиваете, не превысила их число.
В данном примере я использую 100000 строк с кластеризованным индексом и сжатие на генерируемом столбце. Это позволяет ускорить поиск данных.
Замечу, что сжатие индекса может использоваться только в Enterprise версии SQL Server. В противном случае, не используйте эту опцию при создании индекса.
Имея созданную функцию NumbersTest, мы можем написать пользовательскую функцию, реализующую функциональность разбиения массива:
С другой стороны, если мы используем метод CTE, он не потребует таблицы чисел. Вместо нее будет использоваться рекурсивное CTE для извлечения каждой части строки из "остатка" после предыдущей части.
Теперь нам нужно протестировать эти два подхода. Начнем с простого теста для проверки правильности работы:
План выполнения показан ниже. Как видно, функции используют различные методы для достижения одного и того же результата.
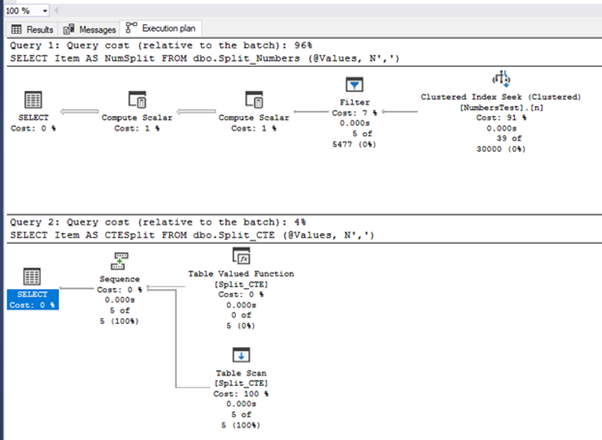
Поскольку набор данных весьма невелик, производительность сравнить невозможно. Давайте проведем тестирование на большем наборе значений.
Сначала нам нужно создать таблицу с тестовыми значениями. Я буду использовать таблицу TestData, и наполню ее различными записями, делая их разных типов с зависимости от категории, к которой они должны быть приписаны:
Когда тестовые данные подготовлены, и функции готовы, мы можем попробовать протестировать их на наборе данных большего размера, чтобы посмотреть производительность функций (для каждого типа данных, в секундах).
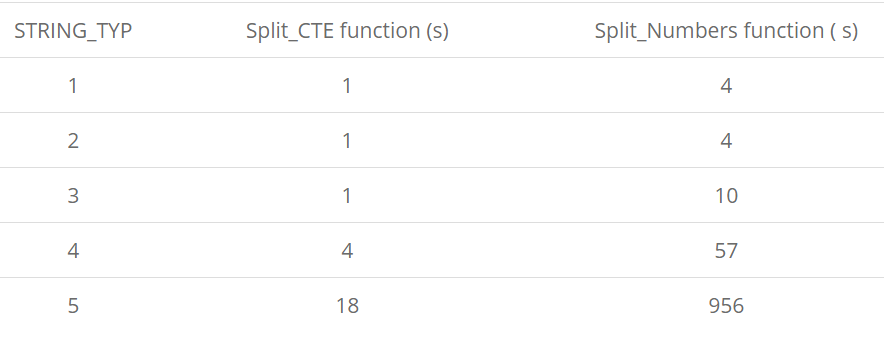
Как показывают результаты, при увеличении строк преимущество метода CTE растет. Его следует предпочесть методу таблицы чисел.
Следует также принять во внимание, что результаты зависят от аппаратного обеспечения машины на сервере.
В SQL Server 2016 появилась новая встроенная функция STRING_SPLIT. Эта функция преобразует строку с разделителями в одностолбцовую таблицу, принимая два параметра: строку для разбиения на значения и символ-разделитель. Она возвращает один столбец с именем value.
Посмотрите пример:
План выполнения для этого запроса ниже:
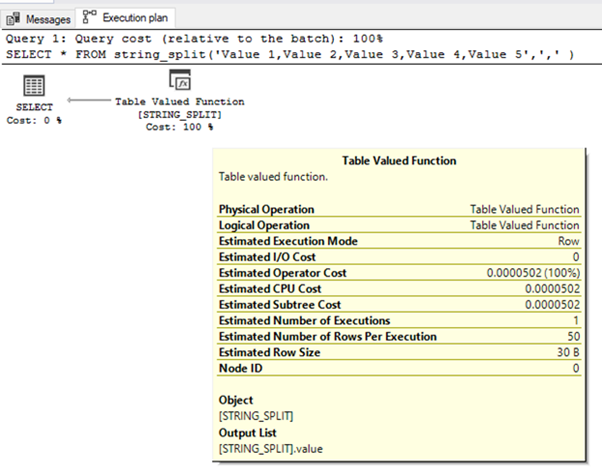
Значение Estimated Number of Rows Per Execution (предполагаемое число строк на выполнение) всегда равно 50. Это не зависит от числа элементов строки.
Если у нас пользовательские табличнозначные функции, оценка числа строк равна 100.
Как табличнозначная функция, она может также использоваться в предложении FROM и выражениях WHERE, и везде, где предполагается табличное выражение.
Например, будем использовать базу данных AdventureWorks2019 для демонстрации применения string_split в операторе JOIN:
Если вы работаете с более новой версией SQL Server, использование списка значений с функцией STRING_SPLIT является оптимальным. Это оптимальное и легкое в использовании решение без потенциальных багов некоторых решений третьих сторон.
Однако имеются некоторые ограничения:
Если эти ограничения приемлемы для вас, спокойно применяйте эту функцию.
Современные методы обработки массивов позволяют правильно решать требуемые задачи. В моей работе я всегда предпочитаю встроенную функцию пользовательской, если они обладают одинаковой производительностью. Она всегда доступна во всех базах данных.
Кроме того, существенно помогают в работе с SQL Server программные инструменты. Они быстрей предоставляют необходимые значения и могут автоматизировать множество задач, которые зачастую отнимают у вас время, которое можно потратить с большей пользой. Например, dbForge SQL Complete предлагает удобную функцию получения значений агрегатов для выбранных данных в сетке результатов SSMS (MIN, MAX, AVG, COUNT и т.д.).
- Табличные переменные не поддерживаются драйверами JDBC, Службы и приложения Java должны использовать разделенные запятыми списки или структурированные форматы типа XML для передачи списка значений на сервер баз данных.
- Унаследованный код по-прежнему работает и необходимо должен поддерживаться, а процессы миграции слишком затратны для реализации.
Чтобы решить эту проблему, специалисты применяют несколько подходов. Некоторые из них включают написание функции CLR .NET или использование XML. Однако, т.к. выполнение функций CLR .NET может быть недоступным во всех средах, а XML обычно является не самым быстрым решением, я остановлюсь на других двух общих подходах. Это методы на основе таблицы чисел и общих табличных выражений (CTE).
Разбиение строки в массив в SQL Server
Подход на основе таблицы чисел означает, что вы должны вручную создать таблицу, содержащую достаточно строк, чтобы самая длинная строка, которую вы разбиваете, не превысила их число.
В данном примере я использую 100000 строк с кластеризованным индексом и сжатие на генерируемом столбце. Это позволяет ускорить поиск данных.
IF EXISTS (
SELECT *
FROM sys.objects
WHERE object_id = OBJECT_ID(N'dbo.NumbersTest')
)
BEGIN
DROP TABLE NumbersTest;
END;
CREATE TABLE NumbersTest (Number INT NOT NULL);
DECLARE @RunDate datetime = GETDATE()
DECLARE @i INT = 1;
WHILE @i <= 100000
BEGIN
INSERT INTO dbo.NumbersTest(Number) VALUES (@i);
SELECT @i = @i + 1;
END;
CREATE UNIQUE CLUSTERED INDEX n ON dbo.NumbersTest(Number) WITH (DATA_COMPRESSION = PAGE);
GOЗамечу, что сжатие индекса может использоваться только в Enterprise версии SQL Server. В противном случае, не используйте эту опцию при создании индекса.
Имея созданную функцию NumbersTest, мы можем написать пользовательскую функцию, реализующую функциональность разбиения массива:
CREATE FUNCTION dbo.Split_Numbers ( @List NVARCHAR(MAX), @Delimiter NVARCHAR(255) )
RETURNS TABLE
WITH SCHEMABINDING
AS
RETURN
(
SELECT Item = SUBSTRING(@List, Number,
CHARINDEX(@Delimiter, @List + @Delimiter, Number) - Number)
FROM dbo.NumbersTest
WHERE Number <= CONVERT(INT, LEN(@List))
AND SUBSTRING(@Delimiter + @List, Number, LEN(@Delimiter)) = @Delimiter); С другой стороны, если мы используем метод CTE, он не потребует таблицы чисел. Вместо нее будет использоваться рекурсивное CTE для извлечения каждой части строки из "остатка" после предыдущей части.
CREATE FUNCTION dbo.Split_CTE ( @List NVARCHAR(MAX), @Delimiter NVARCHAR(255) )
RETURNS @Items TABLE (Item NVARCHAR(4000))
WITH SCHEMABINDING
AS
BEGIN
DECLARE @ll INT = LEN(@List) + 1, @ld INT = LEN(@Delimiter);
WITH a AS
(
SELECT
[start] = 1,
[end] = COALESCE(NULLIF(CHARINDEX(@Delimiter, @List, 1), 0), @ll),
[value] = SUBSTRING(@List, 1,
COALESCE(NULLIF(CHARINDEX(@Delimiter, @List, 1), 0), @ll) - 1)
UNION ALL
SELECT
[start] = CONVERT(INT, [end]) + @ld,
[end] = COALESCE(NULLIF(CHARINDEX(@Delimiter, @List, [end] + @ld), 0), @ll),
[value] = SUBSTRING(@List, [end] + @ld, COALESCE(NULLIF(CHARINDEX(@Delimiter, @List, [end] + @ld), 0), @ll)-[end]-@ld)
FROM a
WHERE [end] < @ll
)
INSERT @Items SELECT [value]
FROM a
WHERE LEN([value]) > 0
OPTION (MAXRECURSION 0);
RETURN;
ENDТеперь нам нужно протестировать эти два подхода. Начнем с простого теста для проверки правильности работы:
DECLARE @Values NVARCHAR(MAX) =N'Value 1,Value 2,Value 3,Value 4,Value 5';
SELECT Item AS NumSplit FROM dbo.Split_Numbers (@Values, N',');
SELECT Item AS CTESplit FROM dbo.Split_CTE (@Values, N',');План выполнения показан ниже. Как видно, функции используют различные методы для достижения одного и того же результата.
Поскольку набор данных весьма невелик, производительность сравнить невозможно. Давайте проведем тестирование на большем наборе значений.
Сначала нам нужно создать таблицу с тестовыми значениями. Я буду использовать таблицу TestData, и наполню ее различными записями, делая их разных типов с зависимости от категории, к которой они должны быть приписаны:
CREATE TABLE dbo.TestData
(
string_typ INT,
string_val NVARCHAR(MAX)
);
CREATE CLUSTERED INDEX st ON dbo.TestData(string_len);
CREATE TABLE #Temp(st NVARCHAR(MAX));
INSERT #Temp
SELECT N'a,va,val,value,value1,valu,va,value12,,valu,value123,value1234';
GO
INSERT dbo.TestData SELECT 1, st FROM #Temp;
GO 10000
INSERT dbo.TestData SELECT 2, REPLICATE(st,10) FROM #Temp;
GO 1000
INSERT dbo.TestData SELECT 3, REPLICATE(st,100) FROM #Temp;
GO 100
INSERT dbo.TestData SELECT 4, REPLICATE(st,1000) FROM #Temp;
GO 10
INSERT dbo.TestData SELECT 5, REPLICATE(st,10000) FROM #Temp;
GO
DROP TABLE #Temp;
GO
-- убираем концевую запятую
UPDATE dbo.TestData
SET string_val = SUBSTRING(string_val, 1, LEN(string_val)-1) + 'x';Когда тестовые данные подготовлены, и функции готовы, мы можем попробовать протестировать их на наборе данных большего размера, чтобы посмотреть производительность функций (для каждого типа данных, в секундах).
SELECT func.Item
FROM dbo.TestData AS tst
CROSS APPLY dbo.Split_CTE(tst.string_val, ',') AS func
WHERE tst.string_typ = 1; -- Значения string_typ от 1-5
SELECT func.Item
FROM dbo.TestData AS tst
CROSS APPLY dbo.Split_Numbers(tst.string_val, ',') AS func
WHERE tst.string_typ = 1; -- Значения string_typ от 1-5Как показывают результаты, при увеличении строк преимущество метода CTE растет. Его следует предпочесть методу таблицы чисел.
Следует также принять во внимание, что результаты зависят от аппаратного обеспечения машины на сервере.
Функции разбиения строк в MS SQL
В SQL Server 2016 появилась новая встроенная функция STRING_SPLIT. Эта функция преобразует строку с разделителями в одностолбцовую таблицу, принимая два параметра: строку для разбиения на значения и символ-разделитель. Она возвращает один столбец с именем value.
Посмотрите пример:
SELECT *
FROM string_split('Value 1,Value 2,Value 3,Value 4,Value 5',',' );План выполнения для этого запроса ниже:
Значение Estimated Number of Rows Per Execution (предполагаемое число строк на выполнение) всегда равно 50. Это не зависит от числа элементов строки.
Если у нас пользовательские табличнозначные функции, оценка числа строк равна 100.
Как табличнозначная функция, она может также использоваться в предложении FROM и выражениях WHERE, и везде, где предполагается табличное выражение.
Например, будем использовать базу данных AdventureWorks2019 для демонстрации применения string_split в операторе JOIN:
USE AdventureWorks2019;
DECLARE @Persons NVARCHAR(4000) = 'Miller,Margheim,Galvin,Duffy,Khanna';
SELECT PersonType, FirstName, MiddleName, LastName
FROM PErson.Person
WHERE LastName IN ( SELECT value FROM string_split(@Persons,',') );Если вы работаете с более новой версией SQL Server, использование списка значений с функцией STRING_SPLIT является оптимальным. Это оптимальное и легкое в использовании решение без потенциальных багов некоторых решений третьих сторон.
Однако имеются некоторые ограничения:
- Принимается только односимвольный разделитель. Если вам требуется больше символов, придется использовать пользовательскую функцию.
- Один выходной столбец - на выходе всегда получается одностолбцовая таблица без позиции элемента строки в строке с разделителями. Это позволяет сортировать только по имени элемента.
- Строковый тип данных - вы используете эту функцию для разделения строки чисел (хотя все значения в выходном столбце являются числами, их типом данных является строка). При соединении из с числовыми столбцами в других таблицах требуется выполнить преобразование типа данных. Если вы забудете выполнить явное преобразование, то можете получить неожиданные результаты.
Если эти ограничения приемлемы для вас, спокойно применяйте эту функцию.
Заключение
Современные методы обработки массивов позволяют правильно решать требуемые задачи. В моей работе я всегда предпочитаю встроенную функцию пользовательской, если они обладают одинаковой производительностью. Она всегда доступна во всех базах данных.
Кроме того, существенно помогают в работе с SQL Server программные инструменты. Они быстрей предоставляют необходимые значения и могут автоматизировать множество задач, которые зачастую отнимают у вас время, которое можно потратить с большей пользой. Например, dbForge SQL Complete предлагает удобную функцию получения значений агрегатов для выбранных данных в сетке результатов SSMS (MIN, MAX, AVG, COUNT и т.д.).
Обратные ссылки
Автор не разрешил комментировать эту запись
Комментарии
Показывать комментарии Как список | Древовидной структурой