
Индексы PostgreSQL: что это такое и как они могут помочь
Пересказ статьи Henrietta Dombrovskaya. PostgreSQL Indexes: What They Are and How They Help
В предыдущей статье этой серии мы узнали, как произвести, прочитать и интерпретировать планы выполнения. Мы узнали, что план выполнения предоставляет информацию о методах доступа, которые PostgreSQL использует для выборки записей из базы данных. В частности, мы видели, что в некоторых случаях PostgreSQL использовал последовательное сканирование, а в некоторых - доступ на основе индекса.
Кажется, что было бы неплохо поговорить об индексах до обсуждения планов выполнения, но планы запросов - это хорошее место для начала движения в сторону решения проблем производительности! Здесь мы собираемся поговорить об индексах, зачем они нам нужны, как они могут нам помочь, и как они могут усугубить ситуацию.
Что такое индекс?
Что такое индекс? Предполагается, что любой человек, кто работает с базами данных, знает, что такое индекс. Однако удивительное число людей, включая разработчиков баз данных и составителей отчетов, а в некоторых случаях даже администраторов, используют индексы, даже создают индексы, лишь смутно понимая, что это такое и какую структуру они имеют. Имея это в виду, давайте начнем с определения того, что есть индекс.
Поскольку имеются разные типы индексов в PostgreSQL (и постоянно создаются новые типы индексов), мы не будем фокусироваться на структурных свойствах в определении индекса. Напротив, мы определяем индекс на основе его использования. Структура данных называется индексом, если это:
- избыточная структура данных
- невидимая для приложения
- предназначенная для ускорения выборки данных на основе определенных критериев
Давайте обсудим каждый из этих пунктов более подробно.
Избыточность означает, что индекс может быть удален без какой-либо потери данных и может быть реконструирован из данных, хранящихся в таблицах (в примерах мы будем использовать дамп базы данных postgres_air, который не содержит индексов, но вы можете построить их после восстановления базы данных. Подробные инструкции содержатся в приложении к этой статье для создания базы данных, которая вам понадобится, если вы захотите выполнять эти примеры).
Невидимость означает, что пользователь не может определить, присутствует или отсутствует индекс при написании запроса, разве что по времени, необходимого для обработки запроса. То есть любой запрос производит одни и те же результаты, есть индекс или нет.
Наконец, индекс создается в надежде (или уверенности), что он улучшит производительность конкретного запроса или (даже лучше!) нескольких запросов. Хотя индексные структуры могут существенно различаться в зависимости от типа, ускорение достигается благодаря быстрой проверки некоторых условий фильтрации, заданных в запросе. Такие условия фильтрации задают определенные ограничения на атрибуты таблицы.
На рисунке 1 показано как индекс может ускорить доступ к указанным строкам таблицы.
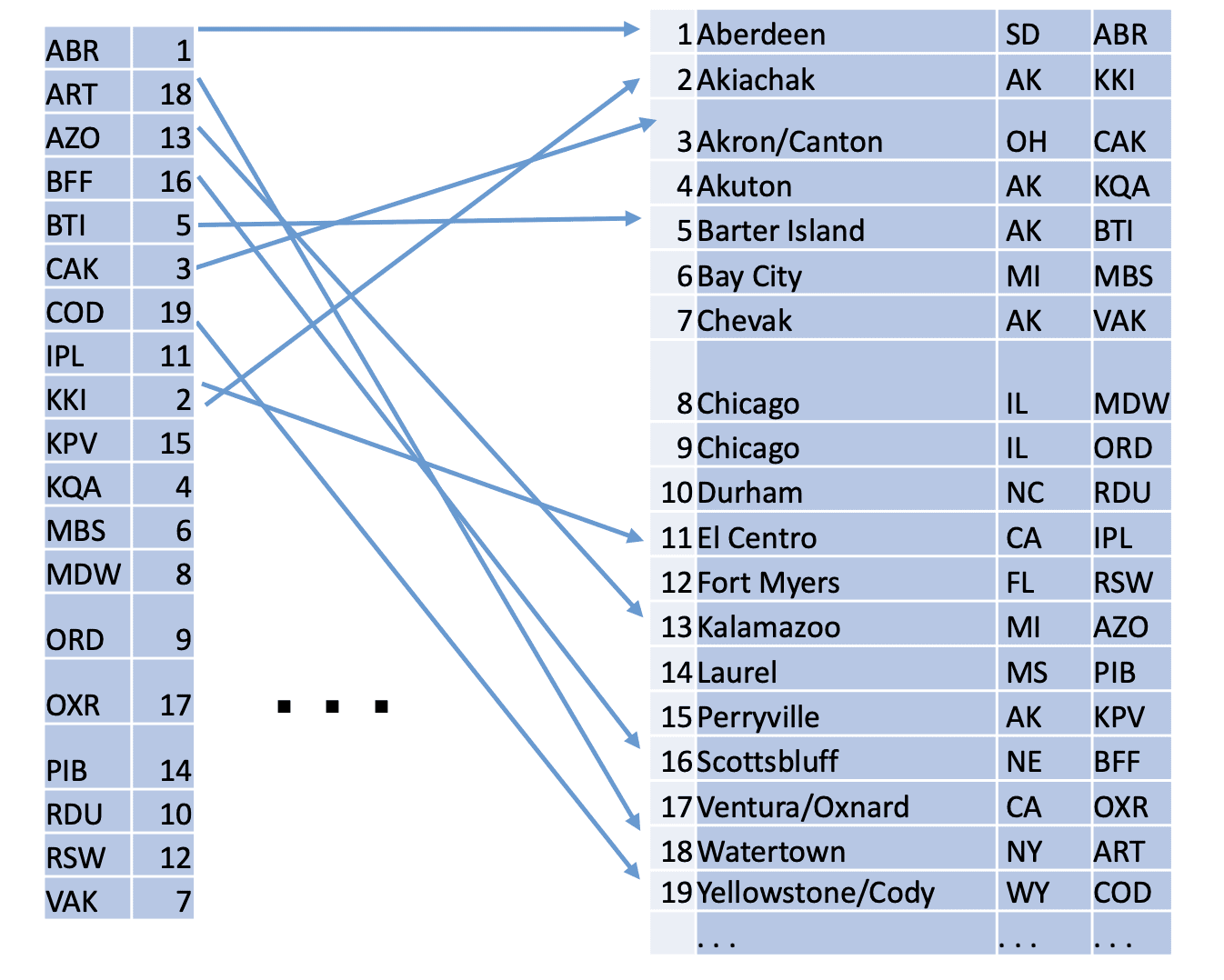
Рис.1 Индексный доступ
Справа на рисунке 1 показана таблица, а слева - индекс, который можно рассматривать как особый тип таблицы. Каждая строка индекса содержит ключ индекса и указатель на строку таблицы. Значение ключа индекса обычно равно значению атрибута таблицы. В примере на рисунке 1 значением ключа является код аэропорта, следовательно, этот индекс поддерживает поиск по коду аэропорта.
Для этого конкретного индекса все значения в столбце airport_code являются уникальными, поэтому каждая запись в индексе указывает ровно на одну строку в таблице. Однако некоторые столбцы, например, столбец city в таблице airport, могут иметь одно и то же значение для множества строк. Если этот столбец проиндексирован, индекс должен содержать указатели на все строки, содержащие это значение ключа индекса. Т.е. ключ может быть логически связан со списком указателей на строки, а не с единственным указателем.
Рисунок 1 иллюстрирует, как достичь соответствующей строки таблицы, когда находится индексная запись, однако он не объясняет, почему строка индекса может быть найдена быстрей, чем строка таблицы. Давайте это выясним.
Типы индексов
PostgreSQL поддерживает множество типов индексов.
В этой статье я собираюсь обсудить только индексы B-Tree, поскольку они имеют наиболее общую структуру, которую вы будете обычно использовать. Имеются другие типы индексов, которые вы можете добавить к таблицам, но B-Tree является наиболее общим, что я и буду обсуждать в этой статье.
Базовая структура B-Tree показана на рисунке 2, где в качестве ключа индекса используются коды аэропортов. Дерево имеет иерархически упорядоченные узлы, которые связаны с блоками, хранящимися на диске.
Записи во всех блоках упорядочены и, по крайней мере, в каждом блоке используется половина его емкости.
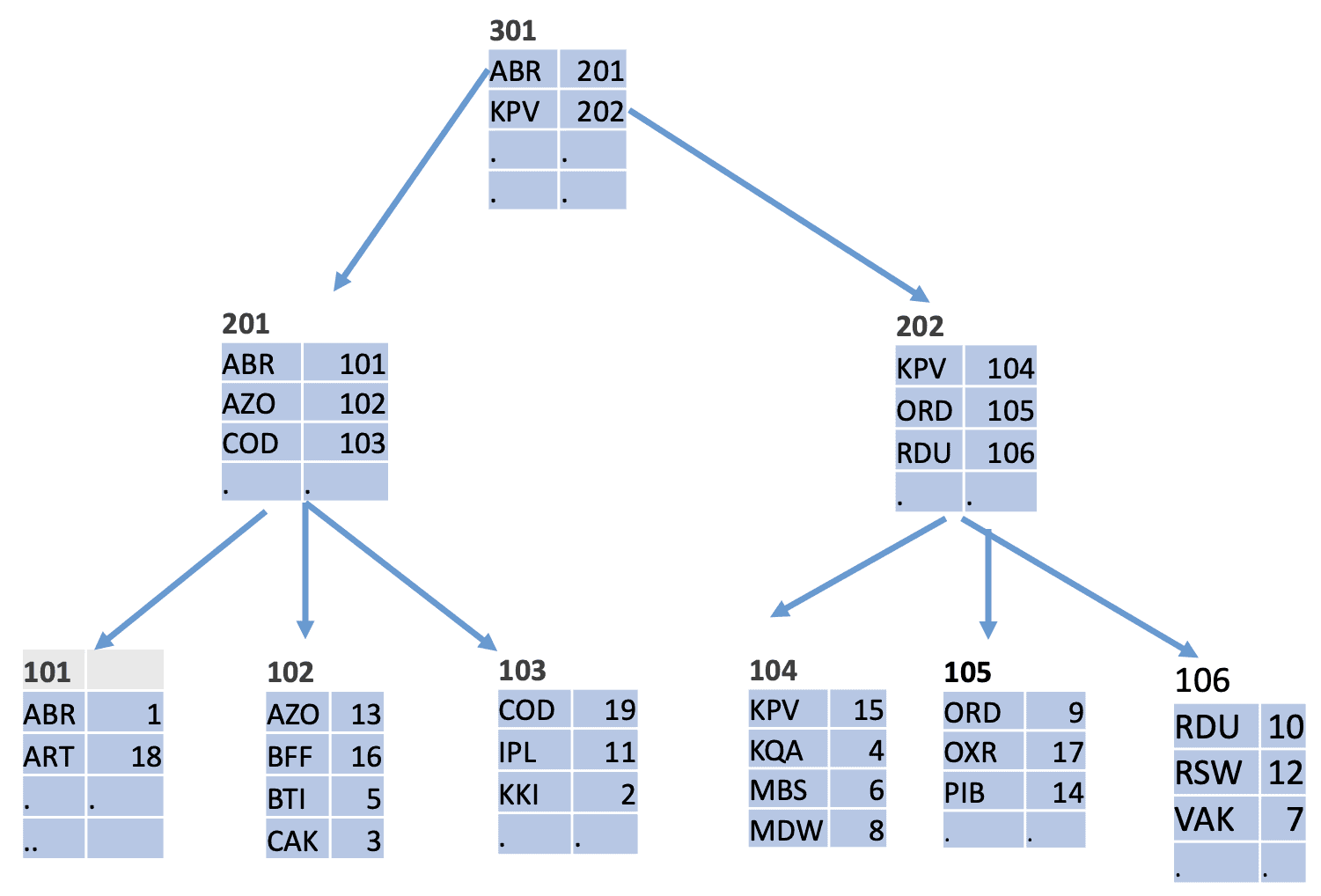
Рис.2 Пример B-Tree
Листовые узлы (показанные в нижнем ряду на рисунке 2) содержат индексные записи, в точности те же самые, что и на рисунке 1; эти записи содержат ключ индекса и указатель на строку таблицы. Нелистовые узлы (находящиеся на всех уровнях за исключением нижнего) содержат записи, которые состоят из наименьшего ключа (на рисунке 2 наименьшее алфавитно-цифровое значение) в блоке, расположенном на следующем уровне, и указатель на этот блок.
Любой поиск ключа К начинается с корневого узла B-Tree. При просмотре блока обнаруживается наибольший ключ Р, не превосходящий К, и поиск продолжается в блоке, на который указывает указатель, связанный с блоком Р, подобным образом поиск продолжается пока не будет достигнут листовой узел, в котором находится указатель, ссылающийся на строки таблицы. Число просмотренных узлов равно глубине дерева. Конечно, ключ К не обязательно хранится в индексе, но поиск находит либо ключ, либо позицию, где он мог бы находиться.
Индексы B-Tree предоставляют широкое разнообразие в использовании (например, поиск отдельной строки и упорядоченного диапазона), и может быть построен для данных любого типа, для которых можно определить упорядочение (иначе называемых порядковыми типами), с этого я и начну эту серию.
Когда индексы полезны
Опираясь на то, что мы уже узнали об индексах, можем мы сказать, что индексы помогают ускорить любой запрос? Совершенно нет! Будет индекс полезен или нет для конкретного запроса главным образом зависит от типа этого запроса. Не удивительно, что индексы большей частью полезны для коротких запросов.
Но подождите - нам требуется дать тут еще одно определение! Какой запрос считается коротким? Зависит ли это от размера запроса? Код ниже очень короткий, означает ли это, что это короткий запрос?
SELECT
d.airport_code AS departure_airport,
a.airport_code AS arrival_airport
FROM airport a,
airport d;Скажу сразу - нет! Этот запрос создает декартово произведение двух копий таблицы airport, генерируя множество всех возможных полетов.
Следующий запрос является "длинным":
SELECT
f.flight_no,
f.scheduled_departure,
boarding_time,
p.last_name,
p.first_name,
bp.update_ts as pass_issued,
ff.level
FROM flight f
JOIN booking_leg bl ON bl.flight_id = f.flight_id
JOIN passenger p ON p.booking_id=bl.booking_id
JOIN account a ON a.account_id =p.account_id
JOIN boarding_pass bp
ON bp.passenger_id=p.passenger_id
LEFT OUTER JOIN frequent_flyer ff
ON ff.frequent_flyer_id=a.frequent_flyer_id
WHERE f.departure_airport = 'JFK'
AND f.arrival_airport = 'ORD'
AND f.scheduled_departure BETWEEN
'2023-08-05' AND '2023-08-07'Однако это короткий запрос, поскольку результат содержит лишь несколько строк.
Может быть число строк на выходе имеет значение? Опять неверно! Посмотрите на следующий запрос:
SELECT
AVG(flight_length),
AVG(passengers)
FROM (SELECT
flight_no,
scheduled_arrival -scheduled_departure
AS flight_length,
COUNT(passenger_id) passengers
FROM flight f
JOIN booking_leg bl ON bl.flight_id = f.flight_id
JOIN passenger p ON p.booking_id=bl.booking_id
GROUP BY 1,2) aЭтот запрос выводит ровно одну строку, однако это длинный запрос, поскольку нам требуется пройти по всем записям в таблицах flight, booking_leg и passenger, чтобы получить результат.
Теперь мы готовы к тому, чтобы дать определение:
Запрос является коротким, когда число необходимых для расчета вывода строк невелико, вне зависимости от величины присутствующих в нем таблиц. Короткие запросы могут читать каждую строку из небольших таблиц, но лишь небольшой процент строк из больших таблиц.
Насколько малым является "небольшой процент"? Это зависит от параметров системы, конкретики приложения, фактических размеров таблиц и, возможно, других факторов. Большую часть времени, однако, это будет менее 10%, соотношения сохраняемых строк к общему количеству строк в таблице. Это соотношение называется селективностью.
На рисунке 3 показан график зависимости между селективностью запроса и стоимостью доступа к данным с индексами и без них.
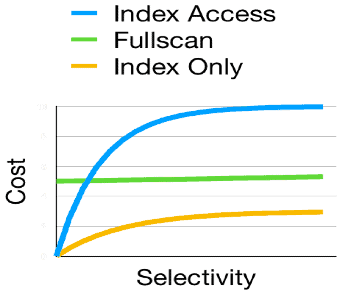
Рис.3 Стоимость по отношению к селективности
Заметим, что PostgreSQL предоставляет два различных метода доступа на основе индекса, каждый из которых будет рассмотрен в этой серии статей.
График на рисунке 3 проясняет, почему индексы наиболее полезны для коротких запросов. Для низко-селективных запросов нам приходится читать небольшое число строк, тем самым уменьшается стоимость дополнительного доступа к индексу. Чем ниже селективность запроса, тем более эффективны индексы. Для запросов с высокой селективностью, стоимость дополнительного доступа к индексу быстро делает его более дорогим, чем последовательное сканирование.
Планы выполнения для коротких запросов
При оптимизации короткого запроса мы знаем, что в конце получим относительно небольшое число записей. Это означает, что целью оптимизации является сокращение размера результирующего набора насколько это возможно. Если большинство ограничивающих выбор критериев применяется на первых шагах выполнения запроса, дальнейшая сортировка, группировка и даже соединения будут менее дорогими. Ищите план выполнения, где не должно быть сканирования больших таблиц. Для маленьких таблиц полное сканирование может еще работать.
Вы не можете быстро выбрать подмножество записей из таблицы, если не существует индекса, поддерживающего соответствующий поиск. Вот почему короткие запросы требуют наличия индексов на больших таблицах для более быстрого выполнения. Если нет индекса для поддержки очень ограничительного запроса, его требуется создать. Может показаться легким делом обеспечить, чтобы наиболее ограничительные критерии выбора выполнялись в первую очередь, однако это не всегда просто.
Посмотрите на следующий запрос:
SELECT *
FROM flight
WHERE departure_airport='LAX'
AND update_ts BETWEEN '2023-08-13' AND '2023-08-15'
AND status='Delayed'
AND scheduled_departure
BETWEEN '2023-08-13' AND '2023-08-15' Можете сказать, какие критерии отбора будут наиболее ограничительными?
Статус "отложенный" (Delayed) может быть наиболее ограничительным, поскольку в идеале в любой заданный день будет значительно больше рейсов, которые выполняются по расписанию.
В нашей учебной базе данных есть расписание полетов за 6 месяцев, поэтому ограничение в два дня может не быть очень ограничительным. С другой стороны, обычно расписание полетов публикуется заранее и, если мы поищем полеты, когда время последнего обновления относительно близко к вылету по расписанию, то очень вероятно, что эти полеты были задержаны или отменены.
Другим фактором, который можно учитывать, является популярность аэропорта, используемого в запросе. LAX - это популярный аэропорт, и ограничение на update_ts будет более ограничительным, чем на departure_airport.
Посмотрите план выполнения!

Можно увидеть, что планировщик запросов PostgreSQL воспользовался тремя индексами на таблице flight и выполнил сканирование побитового индекса - особый тип доступа к данным на основе индекса, который я подробно рассмотрю в следующей статье. Короче говоря, планировщик запросов использует три индекса: flight_departure_airport, flight_update_ts и flight_scheduled_departure. Сканирование этих трех индексов помогает идентифицировать блоки, которые могут потенциально содержать записи, удовлетворяющие критериям поиска, а затем проверяет эти блоки повторно на предмет действительного удовлетворения условий.
Что для нас важно, так это то, что ни один из существующих индексов не имел явного преимущества перед остальными. Значит ли это, что мы не построили наиболее ограничительный индекс? Возможно и так, мы продолжим экспериментировать с дополнительными индексами.
Что если ограничить временной интервал еще больше?
SELECT *
FROM flight
WHERE departure_airport='LAX'
AND update_ts
BETWEEN '2023-08-13' AND '2023-08-14'
AND status='Delayed'
AND scheduled_departure
BETWEEN '2023-08-13' AND '2023-08-14'Как вы думаете, план выполнения останется тем же или изменится?
Действительно изменится!

Теперь условия на update_ts и на scheduled_departure становятся более ограничительными, чем на аэропорт отправления, поэтому только эти два индекса будут использоваться.
Как насчет изменения фильтрации по departure_airport? Если мы изменим его на FUK, критерий для аэропорта станет более ограничительным, чем выбор по update_ts, и план выполнения изменится кардинально:

Как можно увидеть, если все критерии поиска проиндексированы, то нет повода для беспокойства, PostgreSQL будет выбирать оптимальный план выполнения. Но если наиболее ограничительный критерий не проиндексирован, план выполнения может оказаться не оптимальным и, вероятно, потребуется дополнительный индекс.
Накладные расходы на производительность
Улучшение производительности не обходится даром. Так как индекс является вспомогательной структурой, он должен обновляться при обновлении данных в таблице. Этим обусловлены накладные расходы при операциях обновления, чем иногда нельзя пренебречь. Однако многие учебники по базам данных принижают эти накладные расходы. Современные высокопроизводительные СУБД используют алгоритмы, которые уменьшают стоимость обновления индексов, поэтому, как правило, создание нескольких индексов на таблице является выгодным.
Приложение - установка учебной базы данных
Инструкции по установке базы данных можно найти в приложении к первой статье этой серии. Если вы начали с этой статьи, используйте те инструкции для загрузки базы данных.
Эксперименты в этой статье требуют создания следующих дополнительных индексов в вашей копии базы данных postges_air:
SET search_path TO postgres_air;
CREATE INDEX flight_arrival_airport
ON flight (arrival_airport);
CREATE INDEX booking_leg_flight_id
ON booking_leg (flight_id);
CREATE INDEX flight_actual_departure
ON flight (actual_departure);
CREATE INDEX boarding_pass_booking_leg_id
ON boarding_pass (booking_leg_id);
CREATE INDEX booking_update_ts
ON booking (update_ts); Не забудьте выполнить ANALYZE на всех таблицах, для которых вы построили новые индексы:
ANALYZE flight;
ANALYZE booking_leg;
ANALYZE booking;
ANALYZE boarding_pass; Ссылки по теме
1. Секреты индексов и внешних ключей
2. Введение в B-Tree и хэш-индексы в PostgreSQL
3. Типы индексов в PostgreSQL: изучаем PostgreSQL вместе с Grant Fritchey
4. Декартово произведение
5. Сканирование индекса - не всегда плохо, поиск по индексу - не всегда хорошо
6. Индексы: когда селективность столбца не является обязательным требованием
Обратные ссылки
Автор не разрешил комментировать эту запись
Комментарии
Показывать комментарии Как список | Древовидной структурой