Пересказ статьи Nisarg Upadhyay. How to Rename a Column in SQL Server
Недавно я работал над проектом по анализу схемы стороннего поставщика. В нашей организации имелся инструмент управления внутренними тикетами поддержки. Этот инструмент использовал базу данных SQL, и после оценки стоимости инструмента мы решили не возобновлять контракт. Планировалось создать собственный инструмент для управления внутренними тикетами поддержки.
Я должен был сделать обзор схемы базы данных внутренней поддержки. Структура была очень сложной, а имена таблиц таковы, что нам затруднительно было понять, какие данные в каких таблицах хранятся. В конце концов я смог определить связи между таблицами и какие данные там находились. Я также позаботился о том, чтобы дать подходящие имена столбцам, чтобы мы могли легко находить требуемые данные. Я использовал процедуру sp_rename для переименования таблиц.
Эта статья посвящена основам переименования столбцов с помощью хранимой процедуры sp_rename. Также я объясняю, как переименовать столбец, используя SQL Server Management Studio. Сначала давайте разберемся с основами переименования столбца.
Продолжить чтение "Как переименовать столбец в SQL Server"
Пересказ статьи Anjuman Bhattacharyya. Statement Timeout in PostgreSQL
Необходимо предохранять вашу базу данных от долгоиграющих запросов, т.к. они могут подвесить ее. Для защиты вашей базы данных PostgreSQL имеется один конфигурационный параметр, устанавливающий максимально дозволенную длительность любого исполняющегося запроса. Это параметр statement_timeout.
Конфигурационный параметр: statement_timeout
Описание: Устанавливает максимально допустимую продолжительность любого оператора.
Значение по умолчанию: 0 (0 означает, что параметр выключен; обычно измеряется в мс; в основном указывается в мс или сек).
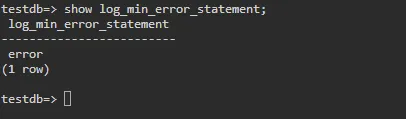
PostgreSQL также записывает в журнал запрос, время ожидания которого истекло, если другой параметр
log_min_error_statement установлен в ERROR. Вы можете проверить это, выполнив следующую команду в вашей базе данных.
 Продолжить чтение "Тайм-аут оператора в PostgreSQL"
Продолжить чтение "Тайм-аут оператора в PostgreSQL"
Пересказ статьи Nathan Rosidi. Integrating Python with SQL for Robust Data Solutions
"Данные - это новая нефть", - говорит Clive Humby. Python и SQL важны для переработки этой нефти, но почему не использовать их совместно?
Для тех, кто ищет решения для манипуляции базами SQL с помощью Python и SQL, мы исследуем различные подходы и используем один из них для создания вопроса для интервью.
Но прежде давайте рассмотрим преимущества и варианты подключения к базам данных с помощью Python.
Продолжить чтение "Интеграция Python с SQL для надежных решений по работе с данными"
§ Популярные темы недели на форуме
Топик Сообщений Просмотров
53 (DML) 4 6
6 (Learn) 3 10
45 (Learn) 2 7
56 (DML) 2 4
§ Авторы недели на форуме
Автор Сообщений
selber 4
_velial 3
nata8ska 2
§ Изменения среди лидеров рейтинга
Рейтинг Участник (решенные задачи)
25 gennadi_s (172)
74 _Bkmz_ (203, 235, 236)
Продолжить чтение "Новости за 2025-06-14 - 2025-06-20"
Пересказ статьи Joydip Kanjilal. SQL Server TRY CATCH, RAISERROR and THROW for Error Handling
Ошибки в приложениях SQL Server могут возникать по разным причинам, таким как ошибочные данные, несогласованность данных, сбой системы или других ошибок. Здесь мы разберем, как обрабатывать ошибки в SQL Server при помощи TRY…CATCH, RAISERROR и THROW.
Логика T-SQL позволяет обрабатывать ошибки в SQL Server разными способами, такими как блоки TRY…CATCH, операторы RAISERROR и THROW. Каждый вариант имеет свои достоинства и недостатки. Давайте рассмотрим примеры для каждого варианта.
Продолжить чтение "TRY CATCH, RAISERROR и THROW для обработки ошибок в SQL Server"
Пересказ статьи hellosqlkitty. ERD Your Existing Databases
Имеется несколько инструментов, чтобы сделать вашу жизнь легче путем создания ERD (диаграмма сущность-связь) для существующих баз данных. Все они работают достаточно хорошо, когда у вас небольшое число таблиц с отображением FK (внешний ключ), но когда число из растет, диаграмма естественно становится значительно грязнее. Вот какие инструменты я испытывал.
Содержание
§ Новая версия sql-tutorial уже доступна, хотя реконструкция еще не завершена. Спешили, как могли. 
Если вы заметите какие-нибудь ошибки, сообщите нам.
§ Изменения среди лидеров рейтинга
Рейтинг Участник (решенные задачи)
28 gennadi_s (171)
80 _Bkmz_ (192, 197, 201, 256)
§ Лидеры недели
Продолжить чтение "Новости за 2025-06-07 - 2025-06-13"
Пересказ статьи Semab Tariq. Performance impact of using ORDER BY with LIMIT in PostgreSQL
При запросах к большим наборам данных в PostgreSQL сочетание предложений ORDER BY и LIMIT может существенно влиять на производительность. ORDER BY сортирует данные, а LIMIT ограничивает число возвращаемых строк, но вместе они создают узкое место в производительности. Понимание взаимодействия этих операций и оптимизация их использования представляется весьма важным для поддержания эффективной производительности базы данных и гарантии быстрого выполнения запросов.
В этой статье мы рассмотрим, как они могут повлиять на производительность запроса.
Ниже приведена структура простой таблицы с именем person, которая будет использоваться в наших тестах.
Продолжить чтение "Влияние на производительность использования ORDER BY с LIMIT в PostgreSQL"
Пересказ статьи lukaseder. Emulating SQL FILTER with Oracle JSON Aggregate Functions
В стандарте SQL:2003 есть крутая функция -
агрегатное предложение FILTER, которое поддерживается естественным образом по крайней мере в этих СУБД:
- ClickHouse
- CockroachDB
- DuckDB
- Firebird
- H2
- HSQLDB
- PostgreSQL
- SQLite
- Trino
- YugabyteDB
Следующая агрегатная функция вычисляет число строк на группу, которая удовлетворяет предложению FILTER:
Продолжить чтение "Эмуляция SQL FILTER с помощью агрегатных функций JSON в Oracle"
§ Изменения среди лидеров рейтинга
Рейтинг Участник (решенные задачи)
29 gennadi_s (170)
§ Лидеры недели
Участник w_sel all_sel select dml Всего Рейтинг
Вольхин С.А. (Sergei Volkhin) 14 85 32 0 32 330
Petrov O.M. (aist13) 15 15 19 0 19 4945
Noname N.N. (Artem74) 14 22 18 0 18 1806
Petrov (fdsadmasc) 14 14 17 0 17 5163
qqqq A.H. (aaaabbbb) 14 14 17 0 17 5168
GMM (gmm_sql) 11 22 14 0 14 3793
Хохлов А.Н. (Хохлов А.Н.) 7 8 10 33 43 2304
Матвеев М. (Матвеев Максим) 4 49 8 0 8 1360
Belskiy V. (Gambit87) 3 34 7 0 7 1415
Макаров И.А. (_Bkmz_) 2 161 6 0 6 93
Иванов К.А. (Монсун) 3 49 6 0 6 1048
Абрамова Ю. (GalaxyTears) 3 43 6 0 6 1446
Продолжить чтение "Новости за 2025-05-31 - 2025-06-06"
Пересказ статьи Tarik Favero. PostgreSQL Execution plan algorithms
В этой статье описываются наиболее общие алгоритмы, которые PostgreSQL может использовать в плане выполнения данного запроса. Примите к сведению, что это не полный список; позднее могут быть добавлены другие алгоритмы.
Алгоритмы пути доступа
Все планы выполнения описывают способ доступа к данным для обеспечения вывода результатов запроса. Поэтому мы обнаружим список операторов, которые выполнялись или будут выполняться для получения результатов.
Мы увидим такие алгоритмы доступа к данным, как Seq Scan, Index Scan, Index-only scan, Bitmap index scan, Bitmap heap scan и их параллельные реализации. В зависимости от условий соединения в JOIN мы увидим алгоритмы комбинации таблиц, такие как Nested loop, Hash-join и Merge. Кроме того, будет представлена информация относительно агрегации, сортировки и буферизации.
Каждый алгоритм имеет свои собственные особенности, которые в зависимости от множества факторов могут оказаться более или менее производительными. Давайте более подробно рассмотрим каждый алгоритм доступа.
Продолжить чтение "Алгоритмы плана выполнения в PostgreSQL"
Пересказ статьи Edward Pollack. Effective Strategies for Storing and Parsing XML in SQL Server
XML представляет собой общепринятый формат хранения для данных, метаданных, параметров или других полуструктурированных данных. По этой причине он часто попадает в базы данных SQL Server и возникает потребность в его обслуживании наряду с другими типами данных.
Несмотря на то, что реляционные базы данных не являются оптимальным местом хранения и обработки данных XML, такая необходимость возникает из-за требований приложения, удобства или необходимости держать эту информацию в непосредственной близости с другими данными приложения.
В этой статье рассматриваются различные распространенные проблемы, связанные с XML, и функциональность, которой обладает SQL Server, чтобы максимально упростить решение этих проблем.
Продолжить чтение "Эффективные стратегии хранения и парсинга XML в SQL Server"
§ Лидеры недели
Участник w_sel all_sel select dml Всего Рейтинг
Новиков С.В. (@Ser589QA) 8 89 18 0 18 366
Вольхин С.А. (Sergei Volkhin) 7 71 17 15 32 437
А Б.В. (dsf4wsfw) 14 14 17 0 17 5161
GMM (gmm_sql) 10 11 14 0 14 5335
Матвеев М. (Матвеев Максим) 5 45 10 0 10 1460
Bulyakarov S. (Sa1avat) 5 130 7 0 7 174
Иванов К.А. (Монсун) 2 46 4 0 4 1114
§ Претенденты на попадание в TOP 100
Рейтинг Участник (решенные задачи, время в днях)
174 Sa1avat (130, 103.199)
345 AstroZomb (83, 4507.944)
366 @Ser589QA (89, 105.854)
Продолжить чтение "Новости за 2025-05-24 - 2025-05-30"
Пересказ статьи Maly Mohsem Ahmed. Enhancing Logging Functionality with PostgreSQL 15’s new JSON Logging Feature
В PostgreSQL появилась новая замечательная функция: журнализация JSON. Хотя журналы JSON занимают больше места, чем журналы в традиционных форматах, они предлагают значительные улучшения, такие как облегчение парсинга и обработки. Эта возможность появилась, начиная с PostgreSQL 15.
Конфигурирование журнализации JSON
Чтобы включить журнализацию JSON, вам необходимо настроить файл postgresql.conf следующим образом:
log_destination = 'jsonlog' # Доступные значения: сочетание stderr, csvlog, jsonlog, syslog и eventlog (независимо от платформы).
logging_collector = on # Требуется для захвата stderr, jsonlog и csvlog в файлы журнала. Это должно быть включено для csvlog и jsonlog.
С этими настройками вывод из журнала может выглядеть следующим образом:
Продолжить чтение "Улучшение функциональности журнализации с помощью новой функции JSON в PostgreSQL 15"
Пересказ статьи DbVisualizer. Using hstore for Storing Unstructured Data in PostgreSQL
В PostgreSQL тип данных hstore является мощным средством для хранения пар ключ-значение в одном столбце, идеальным для управления полуструктурированными и неструктурированными данными. В этой статье дается обзор hstore, содержащий его использование, включение и практические примеры его приложения.
Что такое hstore в PostgreSQL?
hstore позволяет сохранять пары ключ-значение в строковом формате в одном столбце. Эта гибкость идеально удовлетворяет пожеланиям пользователей, хорошо подходит для хранения конфигурационных параметров или метаданных. Вот простой пример:
ALTER TABLE users ADD COLUMN metadata hstore;
Продолжить чтение "Использование hstore для хранения неструктурированных данных в PostgreSQL"
