§ Изменения среди лидеров рейтинга
Рейтинг Участник (решенные задачи)
24 gennadi_s (175, 176)
62 _Bkmz_ (162, 209)
§ Лидеры недели
Участник w_sel all_sel select dml Всего Рейтинг
Максимов И. (igor pupa) 8 36 17 0 17 1351
Харин Е.А. (ekhavlad) 11 11 15 0 15 5353
Куницин С.А. (KU571K) 11 11 14 2 16 5279
Абрамова Ю. (GalaxyTears) 5 49 10 0 10 1294
Noname N.N. (Artem74) 7 56 9 0 9 972
Risunova K. (agen4ik) 4 11 6 9 15 4252
Саркисьян Г. (gennadi_s) 2 186 6 0 6 24
Bulyakarov S. (Sa1avat) 3 139 6 0 6 145
Шитиков А. (Алексей Ш) 4 8 6 0 6 5969
Чудаков А. (an4) 2 33 5 0 5 2134
Коломиенко А.Н. (BackendJedi) 4 4 5 0 5 7450
Кузьмин Е. (evgeniibad) 3 3 4 13 17 5180
Chebykin D. (GriGrim) 2 201 4 0 4 38
Наумов А.Д. (wad881988) 2 96 4 0 4 191
Продолжить чтение "Новости за 2025-07-12 - 2025-07-18"
Пересказ статьи Grant Fritchey. Can AI Read Execution Plans?
Да, да, вторая статья об ИИ подряд. Я обещаю, что это не станет привычкой. Но я видел, что кто-то еще упомянул, что вы можете подать XML, и ИИ прочитает план выполнения. Я должен был протестировать это, а затем поделиться результатами с вами.
Продолжить чтение "Может ли ИИ читать планы выполнения?"
Пересказ статьи Ismail. Using AI to Decode PostgreSQL Query Performance: A Practical Guide

Оптимизация запросов является одной из наиболее сложных сторон работы с базами данных. PostgreSQL дает вам мощные инструменты типа pg_stat_statements и EXPLAIN ANALYZE для понимания и настройки производительности запросов. И хотя эти инструменты содержат ценную информацию, ее бывает сложно интерпретировать - особенно под давлением.
Включите инструменты ИИ. Благодаря возможностям естественного языка и растущего понимания контекста, ИИ может помочь расшифровать то, что стоит за статистикой, выявляя медленные запросы, неэффективные операции и даже предлагая потенциальные улучшения.
В этой статье мы выясним, как можно сочетать исследовательские инструменты PostgreSQL с ИИ, чтобы выполнить настройку более быстро, чисто и продуктивно.
Продолжить чтение "Использование ИИ для декодирования производительности запросов в PostgreSQL: практическое руководство"
§ Популярные темы недели на форуме
Топик Сообщений Просмотров
30 (DML) 7 6
51 (Learn) 2 5
24 (DML) 2 7
§ Авторы недели на форуме
Автор Сообщений
qwrqwr 4
selber 4
§ Изменения среди лидеров рейтинга
Рейтинг Участник (решенные задачи)
67 _Bkmz_ (166, 177)
Продолжить чтение "Новости за 2025-07-05 - 2025-07-11"
Пересказ статьи Lorenzo Uriel. The SQL Week: Bitmasking & Bitwise
Поразрядное маскирование (Bitmasking) и побитовые (Bitwise) операции являются понятиями, используемыми главным образом в программировании для манипуляции и представления данных и объектов на уровне битов, позволяя эффективно их обрабатывать.
Поразрядным маскированием называется процесс использования битовой маски для манипуляции или проверки значения конкретных битов в двоичном числе.
Это делается с помощью побитовых операторов, таких как AND (&), OR (|), XOR (^), NOT (~) и других. Битовые маски используются для определения того, какие биты числа будут модифицироваться, тестироваться или включаться.
Продолжить чтение "Неделя SQL: поразрядное маскирование и побитовые операции"
Пересказ статьи Grant Fritchey. Exploring Window Functions Execution Plans
Есть совсем немного разных способов, с помощью которых вы, вероятно, могли увидеть, как оконные функции проявляют себя в плане выполнения. Давайте рассмотрим один пример.
Оконные функции
Для нашего примера я возьму довольно простой запрос:
SELECT soh.CustomerID,
soh.SubTotal,
ROW_NUMBER() OVER (PARTITION BY soh.CustomerID ORDER BY soh.OrderDate ASC) AS RowNum,
Soh.OrderDate
FROM Sales.SalesOrderHeader AS soh
WHERE soh.OrderDate
BETWEEN '1/1/2013' AND '7/1/2013'
ORDER BY RowNum DESC, soh.OrderDate;
Ничего необычного. Какой план будет сгенерирован? Вот план с метриками времени выполнения (т.е. действительный план):
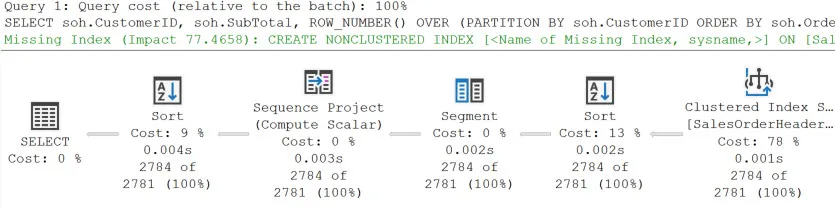 Продолжить чтение "Изучение планов выполнения оконных функций"
Продолжить чтение "Изучение планов выполнения оконных функций"
§ Популярные темы недели на форуме
Топик Сообщений Просмотров
Guest's book 3 23
24 (DML) 2 4
8 (Learn) 2 31
§ Авторы недели на форуме
Автор Сообщений
lutik 5
pegoopik 3
selber 3
gennadi_s 2
Продолжить чтение "Новости за 2025-06-21 - 2025-07-04"
Пересказ статьи Nisarg Upadhyay. How to Rename a Column in SQL Server
Недавно я работал над проектом по анализу схемы стороннего поставщика. В нашей организации имелся инструмент управления внутренними тикетами поддержки. Этот инструмент использовал базу данных SQL, и после оценки стоимости инструмента мы решили не возобновлять контракт. Планировалось создать собственный инструмент для управления внутренними тикетами поддержки.
Я должен был сделать обзор схемы базы данных внутренней поддержки. Структура была очень сложной, а имена таблиц таковы, что нам затруднительно было понять, какие данные в каких таблицах хранятся. В конце концов я смог определить связи между таблицами и какие данные там находились. Я также позаботился о том, чтобы дать подходящие имена столбцам, чтобы мы могли легко находить требуемые данные. Я использовал процедуру sp_rename для переименования таблиц.
Эта статья посвящена основам переименования столбцов с помощью хранимой процедуры sp_rename. Также я объясняю, как переименовать столбец, используя SQL Server Management Studio. Сначала давайте разберемся с основами переименования столбца.
Продолжить чтение "Как переименовать столбец в SQL Server"
Пересказ статьи Anjuman Bhattacharyya. Statement Timeout in PostgreSQL
Необходимо предохранять вашу базу данных от долгоиграющих запросов, т.к. они могут подвесить ее. Для защиты вашей базы данных PostgreSQL имеется один конфигурационный параметр, устанавливающий максимально дозволенную длительность любого исполняющегося запроса. Это параметр statement_timeout.
Конфигурационный параметр: statement_timeout
Описание: Устанавливает максимально допустимую продолжительность любого оператора.
Значение по умолчанию: 0 (0 означает, что параметр выключен; обычно измеряется в мс; в основном указывается в мс или сек).
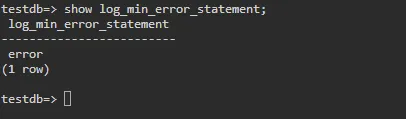
PostgreSQL также записывает в журнал запрос, время ожидания которого истекло, если другой параметр
log_min_error_statement установлен в ERROR. Вы можете проверить это, выполнив следующую команду в вашей базе данных.
 Продолжить чтение "Тайм-аут оператора в PostgreSQL"
Продолжить чтение "Тайм-аут оператора в PostgreSQL"
Пересказ статьи Nathan Rosidi. Integrating Python with SQL for Robust Data Solutions
"Данные - это новая нефть", - говорит Clive Humby. Python и SQL важны для переработки этой нефти, но почему не использовать их совместно?
Для тех, кто ищет решения для манипуляции базами SQL с помощью Python и SQL, мы исследуем различные подходы и используем один из них для создания вопроса для интервью.
Но прежде давайте рассмотрим преимущества и варианты подключения к базам данных с помощью Python.
Продолжить чтение "Интеграция Python с SQL для надежных решений по работе с данными"
§ Популярные темы недели на форуме
Топик Сообщений Просмотров
53 (DML) 4 6
6 (Learn) 3 10
45 (Learn) 2 7
56 (DML) 2 4
§ Авторы недели на форуме
Автор Сообщений
selber 4
_velial 3
nata8ska 2
§ Изменения среди лидеров рейтинга
Рейтинг Участник (решенные задачи)
25 gennadi_s (172)
74 _Bkmz_ (203, 235, 236)
Продолжить чтение "Новости за 2025-06-14 - 2025-06-20"
Пересказ статьи Joydip Kanjilal. SQL Server TRY CATCH, RAISERROR and THROW for Error Handling
Ошибки в приложениях SQL Server могут возникать по разным причинам, таким как ошибочные данные, несогласованность данных, сбой системы или других ошибок. Здесь мы разберем, как обрабатывать ошибки в SQL Server при помощи TRY…CATCH, RAISERROR и THROW.
Логика T-SQL позволяет обрабатывать ошибки в SQL Server разными способами, такими как блоки TRY…CATCH, операторы RAISERROR и THROW. Каждый вариант имеет свои достоинства и недостатки. Давайте рассмотрим примеры для каждого варианта.
Продолжить чтение "TRY CATCH, RAISERROR и THROW для обработки ошибок в SQL Server"
Пересказ статьи hellosqlkitty. ERD Your Existing Databases
Имеется несколько инструментов, чтобы сделать вашу жизнь легче путем создания ERD (диаграмма сущность-связь) для существующих баз данных. Все они работают достаточно хорошо, когда у вас небольшое число таблиц с отображением FK (внешний ключ), но когда число из растет, диаграмма естественно становится значительно грязнее. Вот какие инструменты я испытывал.
Содержание
§ Новая версия sql-tutorial уже доступна, хотя реконструкция еще не завершена. Спешили, как могли. 
Если вы заметите какие-нибудь ошибки, сообщите нам.
§ Изменения среди лидеров рейтинга
Рейтинг Участник (решенные задачи)
28 gennadi_s (171)
80 _Bkmz_ (192, 197, 201, 256)
§ Лидеры недели
Продолжить чтение "Новости за 2025-06-07 - 2025-06-13"
Пересказ статьи Semab Tariq. Performance impact of using ORDER BY with LIMIT in PostgreSQL
При запросах к большим наборам данных в PostgreSQL сочетание предложений ORDER BY и LIMIT может существенно влиять на производительность. ORDER BY сортирует данные, а LIMIT ограничивает число возвращаемых строк, но вместе они создают узкое место в производительности. Понимание взаимодействия этих операций и оптимизация их использования представляется весьма важным для поддержания эффективной производительности базы данных и гарантии быстрого выполнения запросов.
В этой статье мы рассмотрим, как они могут повлиять на производительность запроса.
Ниже приведена структура простой таблицы с именем person, которая будет использоваться в наших тестах.
Продолжить чтение "Влияние на производительность использования ORDER BY с LIMIT в PostgreSQL"
